
OpenAI’s newest AI mannequin household has achieved what many thought unattainable, scoring an unprecedented 87.5% on the difficult, so-called Autonomous Analysis Collaborative Synthetic Basic Intelligence benchmark—principally close to the minimal threshold for what might theoretically be thought-about “human.”
The ARC-AGI benchmark checks how shut a mannequin is to reaching synthetic normal intelligence, that means whether or not it could actually assume, remedy issues, and adapt like a human in several conditions… even when it hasn’t been skilled for them. The benchmark is extraordinarily straightforward for people to beat, however is extraordinarily onerous for machines to know and remedy.
The San Francisco-based AI analysis firm unveiled o3 and o3-mini final week as a part of its “12 days of OpenAI” marketing campaign—and simply days after Google introduced its personal o1 competitor. The discharge confirmed that OpenAI’s upcoming mannequin was nearer to reaching synthetic normal intelligence than anticipated.
OpenAI’s new reasoning-focused mannequin marks a basic shift in how AI techniques strategy complicated reasoning. In contrast to conventional giant language fashions that depend on sample matching, o3 introduces a novel “program synthesis” strategy that permits it to deal with fully new issues it hasn’t encountered earlier than.
“This isn’t merely incremental enchancment, however a real breakthrough,” the ARC staff acknowledged of their analysis report. In a weblog publish, ARC Prize co-founder Francois Chollet went even additional, suggesting that “o3 is a system able to adapting to duties it has by no means encountered earlier than, arguably approaching human-level efficiency within the ARC-AGI area.”
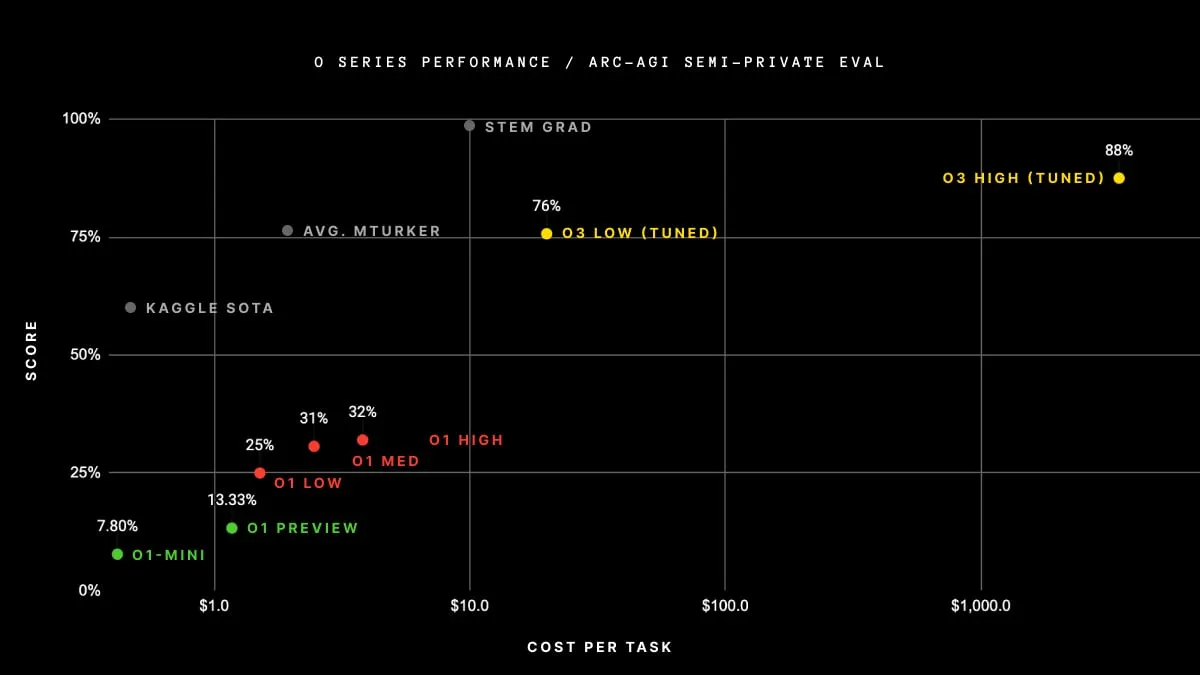
Only for reference, here’s what ARC Prize says about its scores: “The typical human efficiency within the examine was between 73.3% and 77.2% right (public coaching set common: 76.2%; public analysis set common: 64.2%.)”
OpenAI o3 achieved an 88.5% rating utilizing excessive computing tools. That rating was leaps forward of every other AI mannequin presently accessible.
Is o3 AGI? It will depend on who you ask
Regardless of its spectacular outcomes, the ARC Prize board—and different consultants—mentioned that AGI has not but been achieved, so the $1 million prize stays unclaimed. However consultants throughout the AI trade weren’t unanimous of their opinions about whether or not o3 had breached the AGI benchmark.
Some—together with Chollet himself—took subject with the whether or not the benchmarking take a look at itself was even the perfect gauge of whether or not a mannequin was approaching actual, human-level problem-solving: “Passing ARC-AGI doesn’t equate to reaching AGI, and as a matter of reality, I do not assume o3 is AGI but,” Chollet mentioned. “O3 nonetheless fails on some very straightforward duties, indicating basic variations with human intelligence.”
He referenced a more recent model of the AGI benchmark, which he mentioned would offer a extra correct measure of how shut an AI is to with the ability to cause like a human. Chollet famous that “early knowledge factors recommend that the upcoming ARC-AGI-2 benchmark will nonetheless pose a big problem to o3, doubtlessly decreasing its rating to underneath 30% even at excessive compute (whereas a wise human would nonetheless be capable of rating over 95% with no coaching).”
Different skeptics even claimed that OpenAI successfully gamed the take a look at. “Fashions like o3 use planning tips. They define steps (“scratchpads”) to enhance accuracy, however they’re nonetheless superior textual content predictors. For instance, when o3 ‘counts letters,’ it’s producing textual content about counting, not actually reasoning,” Zeroqode co-founder Levon Terteryan wrote on X.
Why OpenAI’s o3 Isn’t AGI
OpenAI’s new reasoning mannequin, o3, is spectacular on benchmarks however nonetheless removed from AGI.
What’s AGI?
AGI (Synthetic Basic Intelligence) refers to a system able to human-level understanding throughout duties. It ought to:
– Play chess like a human.… pic.twitter.com/yn4cuDTFte— Levon Terteryan (@levon377) December 21, 2024
An analogous standpoint is shared by different AI scientists, just like the award-winning AI researcher Melanie Mitchel, who argued that o3 isn’t actually reasoning however performing a “heuristic search.”
Chollet and others identified that OpenAI wasn’t clear about how its fashions function. The fashions seem like skilled on completely different Chain of Thought processes “in a vogue maybe not too dissimilar to AlphaZero-style Monte-Carlo tree search,” mentioned Mitchell. In different phrases, it doesn’t know remedy a brand new drawback, and as an alternative applies the most definitely Chain of Thought attainable on its huge corpus on data till it efficiently finds an answer.
In different phrases, o3 isn’t actually inventive—it merely depends on an enormous library to trial-and-error its option to an answer.
“Brute pressure (doesn’t equals) intelligence. o3 relied on excessive computing energy to achieve its unofficial rating,” Jeff Joyce, host of the Humanity Unchained AI podcast, argued on Linkedin. “True AGI would want to resolve issues effectively. Even with limitless assets, o3 couldn’t crack over 100 puzzles that people discover straightforward.”
OpenAI researcher Vahidi Kazemi is within the “That is AGI” camp. “In my view now we have already achieved AGI,” he mentioned, pointing to the sooner o1 mannequin, which he argued was the primary designed to cause as an alternative of simply predicting the following token.
He drew a parallel to scientific methodology, contending that since science itself depends on systematic, repeatable steps to validate hypotheses, it’s inconsistent to dismiss AI fashions as non-AGI just because they observe a set of predetermined directions. That mentioned, OpenAI has “not achieved ‘higher than any human at any process,’ ” he wrote.
In my view now we have already achieved AGI and it’s much more clear with O1. We’ve got not achieved “higher than any human at any process” however what now we have is “higher than most people at most duties”. Some say LLMs solely know observe a recipe. Firstly, nobody can actually clarify…
— Vahid Kazemi (@VahidK) December 6, 2024
For his half, OpenAI CEO Sam Altman isn’t taking a place on whether or not AGI has been reached. He merely mentioned that “o3 is a really very sensible mannequin,” and “o3 mini is an extremely sensible mannequin however with actually good efficiency and value.”
Being sensible is probably not sufficient to say that AGI has been achieved—no less than but. However keep tuned: “We view this as kind of the start of the following part of AI,” he added.
Edited by Andrew Hayward
Typically Clever Publication
A weekly AI journey narrated by Gen, a generative AI mannequin.