
A workforce of worldwide researchers from main educational establishments and tech corporations upended the AI reasoning panorama on Wednesday with a brand new mannequin that matched—and sometimes surpassed—considered one of China’s most subtle AI programs: DeepSeek.
OpenThinker-32B, developed by the Open Ideas consortium, achieved a 90.6% accuracy rating on the MATH500 benchmark, edging previous DeepSeek’s 89.4%.
The mannequin additionally outperformed DeepSeek on common problem-solving duties, scoring 61.6 on the GPQA-Diamond benchmark in comparison with DeepSeek’s 57.6. On the LCBv2 benchmark, it hit a stable 68.9, displaying sturdy efficiency throughout various testing situations.
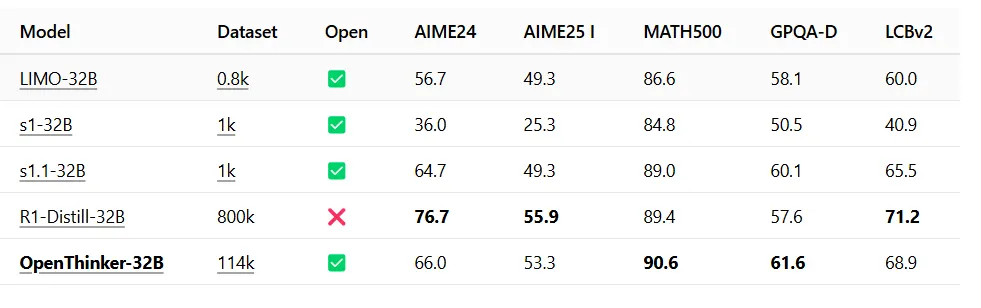
In different phrases, it’s higher than a similarly-sized model of DeepSeek R1 at common scientific information (GPQA-Diamond). It additionally beat DeepSeek at MATH500 whereas shedding on the AIME benchmarks—each of which attempt to measure math proficiency.
It’s additionally a bit worse than DeepSeek at coding, scoring 68.9 factors vs 71.2, however because the mannequin is open supply, all these scores can drastically get higher as soon as folks begin enhancing upon it.
What set this achievement aside was its effectivity: OpenThinker required solely 114,000 coaching examples to succeed in these outcomes, whereas DeepSeek used 800,000.
The OpenThoughts-114k dataset got here filled with detailed metadata for every drawback: floor reality options, take a look at circumstances for code issues, starter code the place wanted, and domain-specific data.
Its customized Curator framework validated code options in opposition to take a look at circumstances, whereas an AI choose dealt with math verification.
The workforce reported it used 4 nodes geared up with eight H100 GPUs, finishing in roughly 90 hours. A separate dataset with 137,000 unverified samples, skilled on Italy’s Leonardo Supercomputer, burned via 11,520 A100 hours in simply 30 hours.
“Verification serves to take care of high quality whereas scaling up range and dimension of coaching prompts,” the workforce famous of their documentation. The analysis indicated that even unverified variations carried out effectively, although they didn’t match the verified mannequin’s peak outcomes.
The mannequin was constructed on prime of Alibaba’s Qwen2.5-32B-Instruct LLM and helps a modest 16,000-token context window—sufficient to deal with complicated mathematical proofs and prolonged coding issues however rather a lot lower than the present requirements.
This launch arrives amid intensifying competitors in AI reasoning capabilities, which appears to be occurring on the velocity of thought. OpenAI introduced on February 12 that each one fashions following GPT-5 would function reasoning capabilities. In the future later, Elon Musk puffed up xAI’s Grok-3’s enhanced problem-solving capabilities, promising it could be one of the best reasoning mannequin so far, and only a few hours in the past, Nous Analysis launched one other open-source reasoning mannequin, DeepHermes, based mostly on Meta’s Llama 3.1.
The sphere gained momentum after DeepSeek demonstrated comparable efficiency to OpenAI’s o1 at considerably diminished prices. DeepSeek R1 is free to obtain, use, and modify, with the coaching strategies additionally revealed.
Nonetheless, in contrast to Open Ideas, which determined to open supply every thing, the DeepSeek improvement workforce saved its coaching knowledge personal.
This key distinction means builders could have a better time understanding OpenThinker and reproducing its outcomes from scratch than they might have with DeepSeek as a result of they’ve entry to all of the items of the puzzle.
For the broader AI group, this launch demonstrates as soon as once more the viability of constructing aggressive fashions with out large proprietary datasets. Additionally, it might be a extra trusty competitor for Western builders who’re nonetheless not sure about utilizing a Chinese language mannequin—open supply or not.
OpenThinker is offered for obtain at HuggingFace. A smaller, much less highly effective 7B parameter mannequin can be out there for lower-end units.
The Open Ideas workforce pulled collectively researchers from completely different American universities, together with Stanford, Berkeley, and UCLA, alongside Germany’s Juelich Supercomputing Middle. The US-based Toyota Analysis Institute and different gamers within the EU AI scene additionally again it.
Edited by Josh Quittner and Sebastian Sinclair
Usually Clever Publication
A weekly AI journey narrated by Gen, a generative AI mannequin.