
Google quietly rolled out a strong new model of Gemini final week that lets anybody edit pictures utilizing plain English instructions as a substitute of technical abilities. The experimental model of Gemini 2.0 Flash with native picture technology capabilities is now accessible to all customers after being restricted to testers solely since final 12 months.
Not like most present AI picture instruments, this is not nearly producing new photographs from scratch. Google has created a system that understands present pictures effectively sufficient to change them by way of pure dialog, sustaining a lot of the unique content material whereas making particular modifications.
That is attainable as a result of Gemini 2.0 is natively multimodal, that means it could perceive each textual content and pictures concurrently. The mannequin converts photographs into tokens—the identical primary models it makes use of to course of textual content—permitting it to govern visible content material utilizing the identical neural pathways it makes use of to grasp language. This unified strategy means the system does not have to name separate specialised fashions to deal with totally different media varieties.
“Gemini 2.0 Flash combines multimodal enter, enhanced reasoning, and pure language understanding to create photographs,” Google stated within the official announcement. “Use Gemini 2.0 Flash to inform a narrative and it’ll illustrate it with footage, holding the characters and settings constant all through. Give it suggestions and the mannequin will retell the story or change the type of its drawings.”
Google’s strategy differs considerably from rivals like OpenAI, whose ChatGPT can generate photographs utilizing Dall-E 3 and iterate on its creations understanding pure language—however requires a separate AI mannequin to take action. In different phrases, ChatGPT coordinates between GPT-V for imaginative and prescient, GPT-4o for language, and Dall-E 3 for picture technology, as a substitute of getting one mannequin to grasp all the pieces—which is what OpenAI expects to realize with GPT-5.
An identical idea exists within the open-source world by way of OmniGen, developed by researchers on the Beijing Academy of Synthetic Intelligence. Its creators envision “producing numerous photographs instantly by way of arbitrarily multimodal directions with out the necessity for added plugins and operations, just like how GPT works in language technology.”
OmniGen can also be able to altering objects, merging parts into one scene, and coping with aesthetics. For instance, we examined the mannequin again in 2024 and had been in a position to generate a picture of Decrypt co-founder Josh Quittner hanging out with Ethereum co-founder Vitalik Buterin.

Nonetheless, OmniGen is so much much less user-friendly, works with smaller resolutions, requires extra advanced instructions, and isn’t as highly effective as the brand new Gemini. Nonetheless, it’s an ideal open-source various that could be attention-grabbing for some customers.
Here is what we discovered with Google’s Gemini 2.0 Flash, nevertheless.
Testing the mannequin
We put Gemini 2.0 Flash by way of its paces to see the way it performs throughout totally different modifying eventualities. The outcomes reveal each spectacular capabilities and a few notable limitations.
Sensible topics
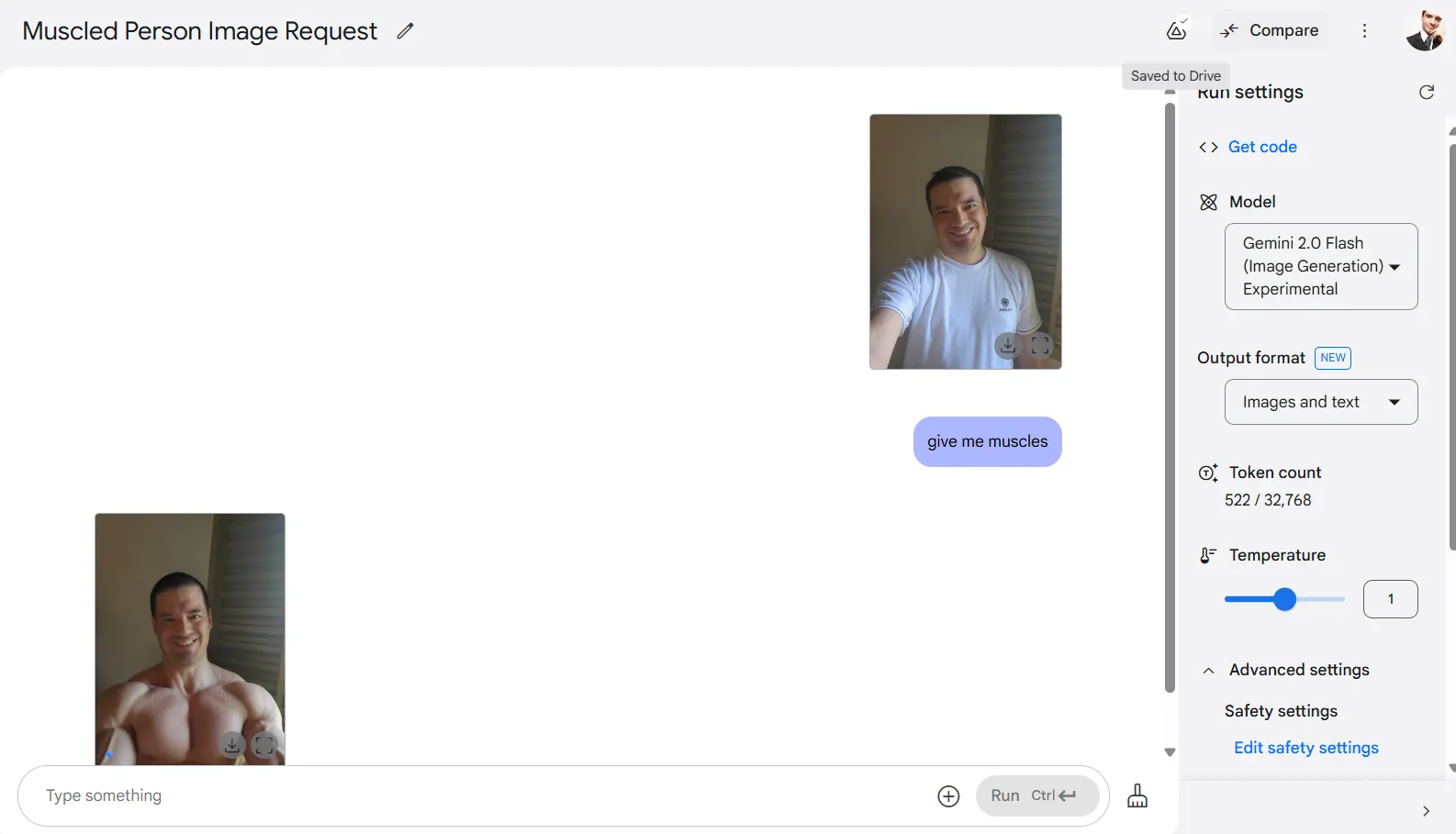
The mannequin maintains stunning coherence when modifying real looking topics. In my exams, I uploaded a self-portrait and requested it so as to add muscle tissues. The AI delivered as requested, and whereas my face modified barely, it remained recognizable.
Different parts within the photograph stayed largely unchanged, with the AI focusing solely on the precise modification requested. This focused modifying means stands out in comparison with typical generative approaches that usually recreate whole photographs.
The mannequin can also be censored, usually refusing to edit pictures of kids and refusing to deal with nudity, after all. In spite of everything, it is a mannequin by Google. If you wish to get naughty with grownup pictures, then OmniGen is your pal.
Type transformations
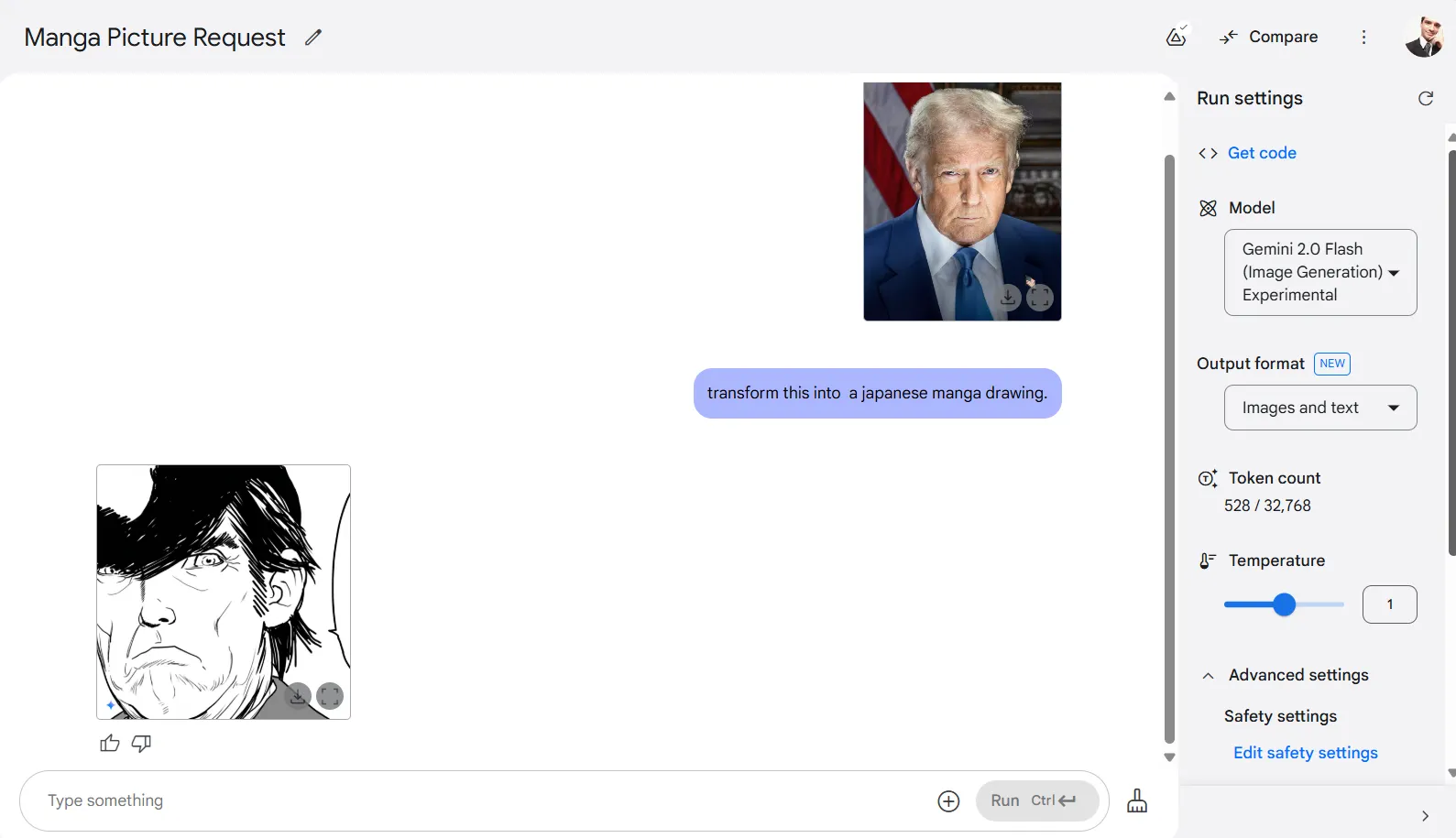
Gemini 2.0 Flash exhibits an excellent aptitude for type conversions. When requested to rework a photograph of Donald Trump into Japanese manga type, it efficiently reimagined the picture after just a few makes an attempt.
The mannequin handles a variety of fashion transfers—turning pictures into drawings, oil work, or just about any artwork type you possibly can describe. You may fine-tune outcomes by adjusting temperature settings and toggling filters, although greater temperature settings have a tendency to provide much less recognizable transformations of the unique.
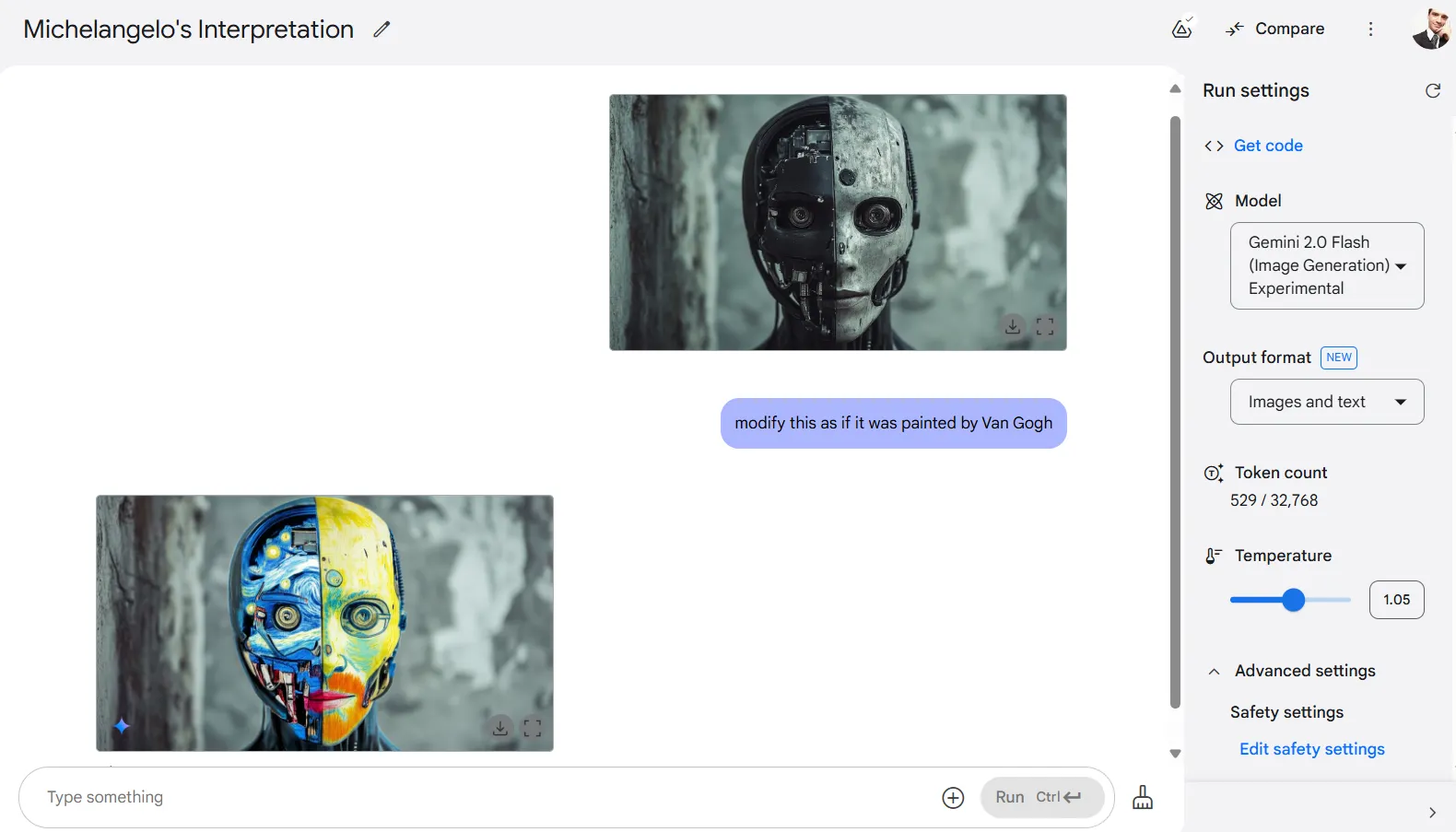
One limitation, nevertheless, occurs when requesting artist-specific kinds. Assessments asking the mannequin to use the kinds of Leonardo Da Vinci, Michelangelo, Botticelli, or Van Gogh resulted within the AI reproducing precise work by these artists quite than making use of their strategies to the supply picture.
After some immediate tweaks and few reruns, we had been in a position to get a mediocre however usable end result. Ideally, as a substitute of prompting the artist, it’s higher to immediate the artwork type.
Aspect manipulation
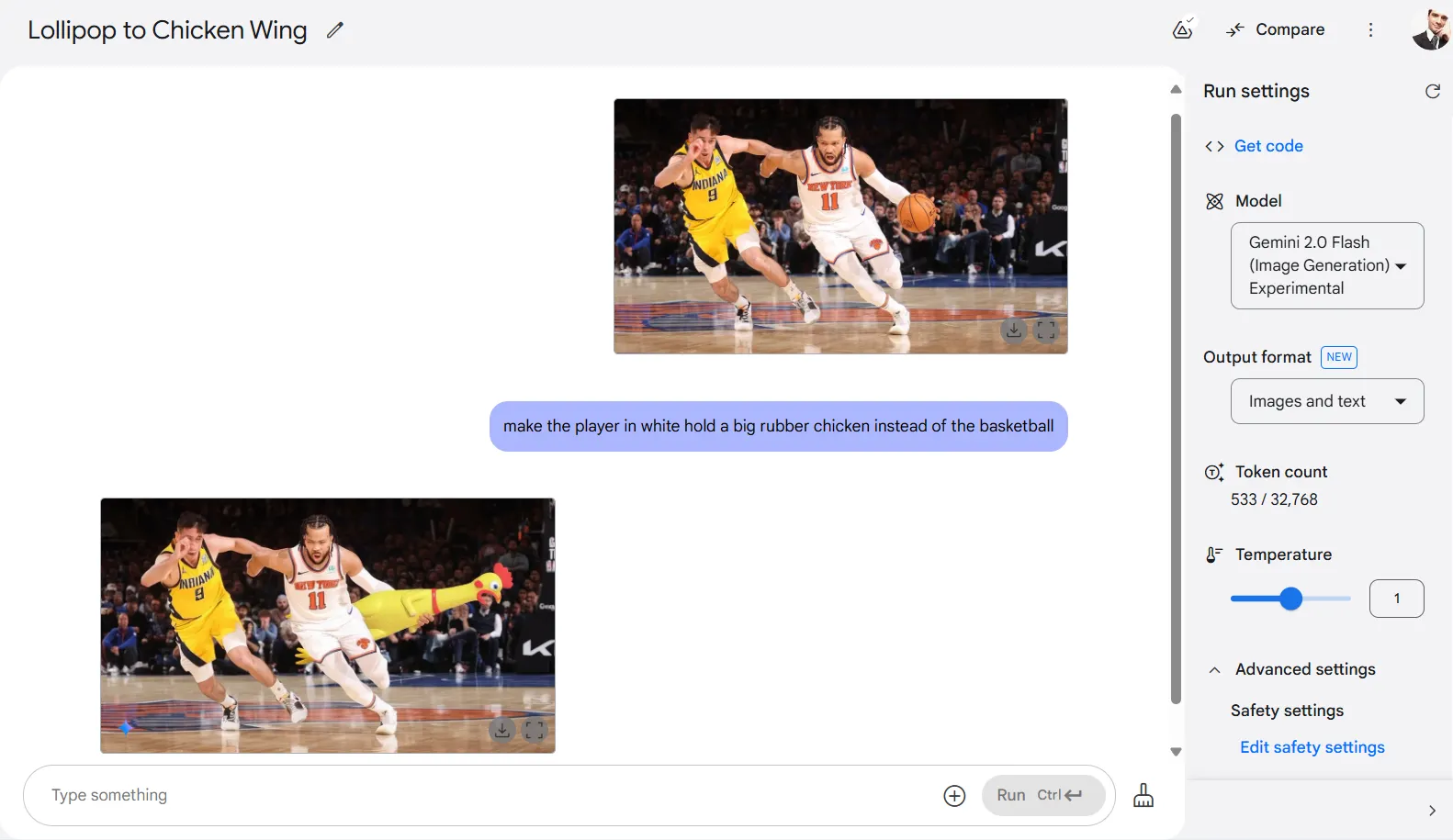
For sensible modifying duties, the mannequin really shines. It expertly handles inpainting and object manipulation—eradicating particular objects when requested, or including new parts to a composition. In a single take a look at, we prompted the AI to interchange a basketball with an enormous rubber hen for some motive, and it delivered a humorous but contextually acceptable end result.
Generally it could alter particular bits of the topics, however this is a matter that’s simply fixable with digital modifying instruments in just a few seconds.
Truthfully, we don’t know what we anticipated after asking it to make basketball gamers combat for a rubber hen.
Maybe most controversially, the mannequin is excellent at eradicating copyright protections—a characteristic that was broadly talked about on X. After we uploaded a picture with watermarks and requested it to delete all letters, logos, and watermarks, Gemini produced a clear picture that appeared similar to the un-watermarked authentic.
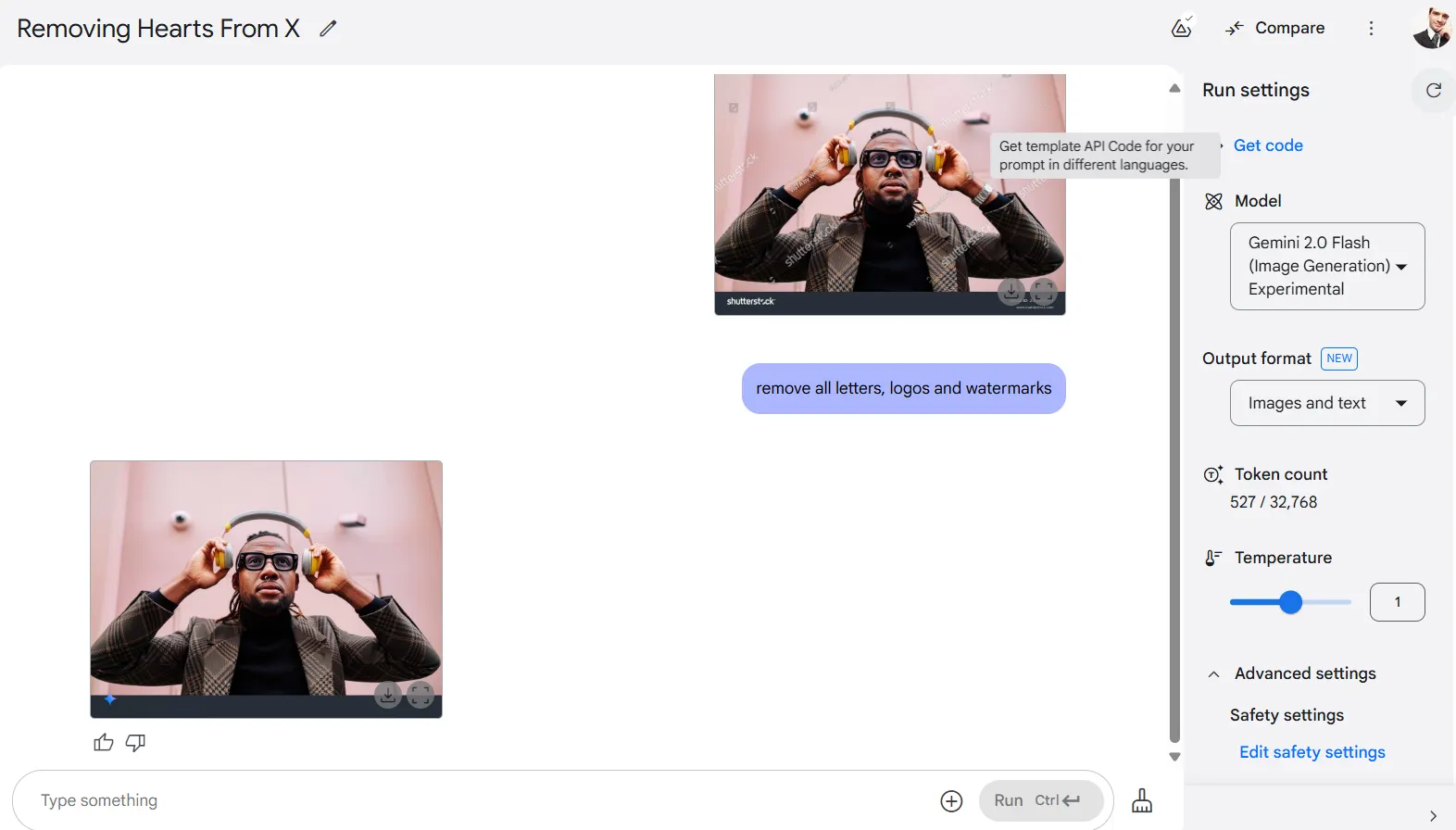
Perspective modifications
One of the crucial technically spectacular feats is Gemini’s means to vary perspective—one thing mainstream diffusion fashions can’t do. The AI can reimagine a scene from totally different angles, although the outcomes are primarily new creations quite than exact transformations.
Whereas perspective shifts do not ship excellent outcomes—in spite of everything, the mannequin is conceptualizing 100% of the picture whereas rendering it from new viewpoints—they signify a major advance in AI’s understanding of three-dimensional house from two-dimensional inputs.
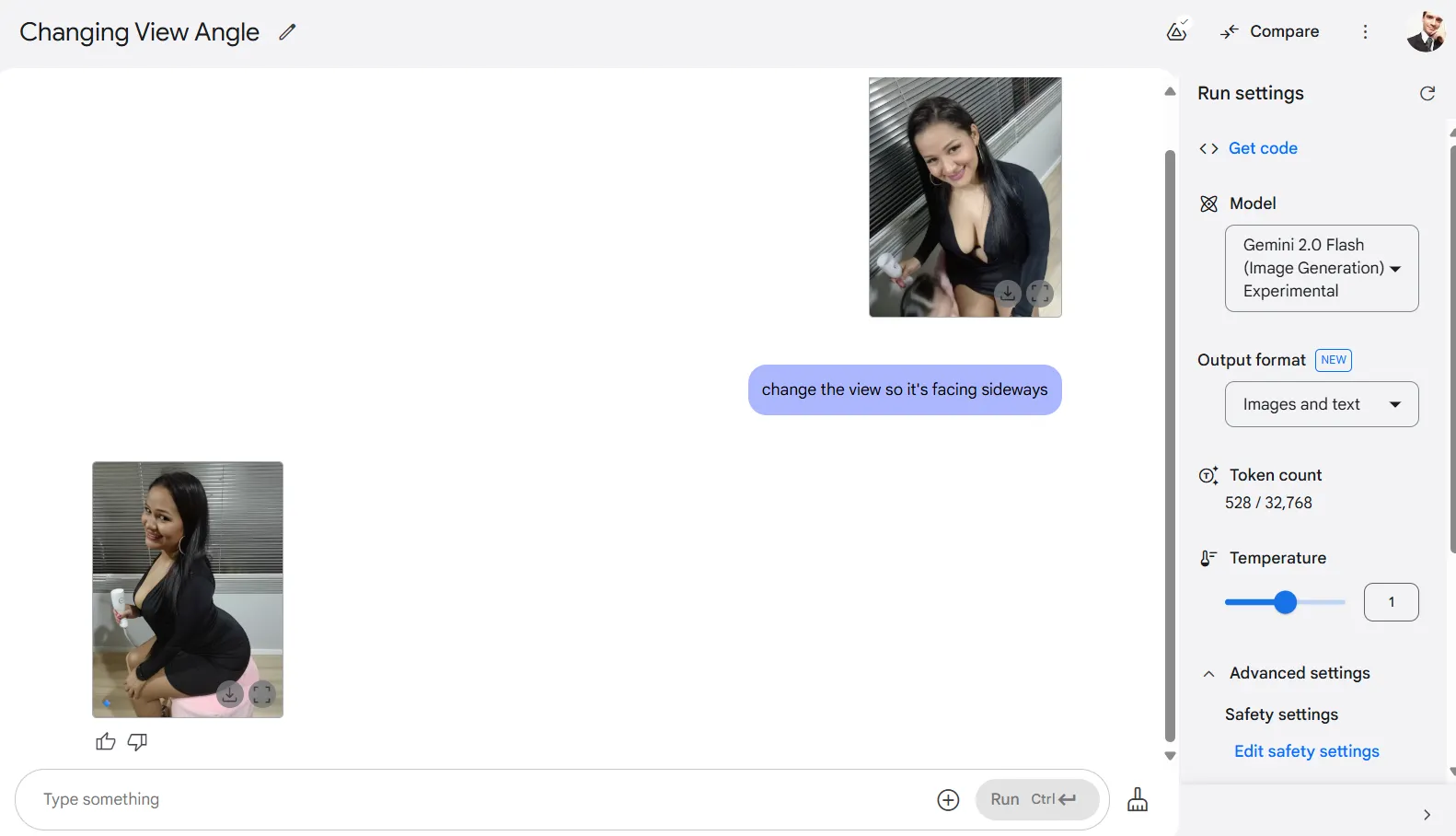
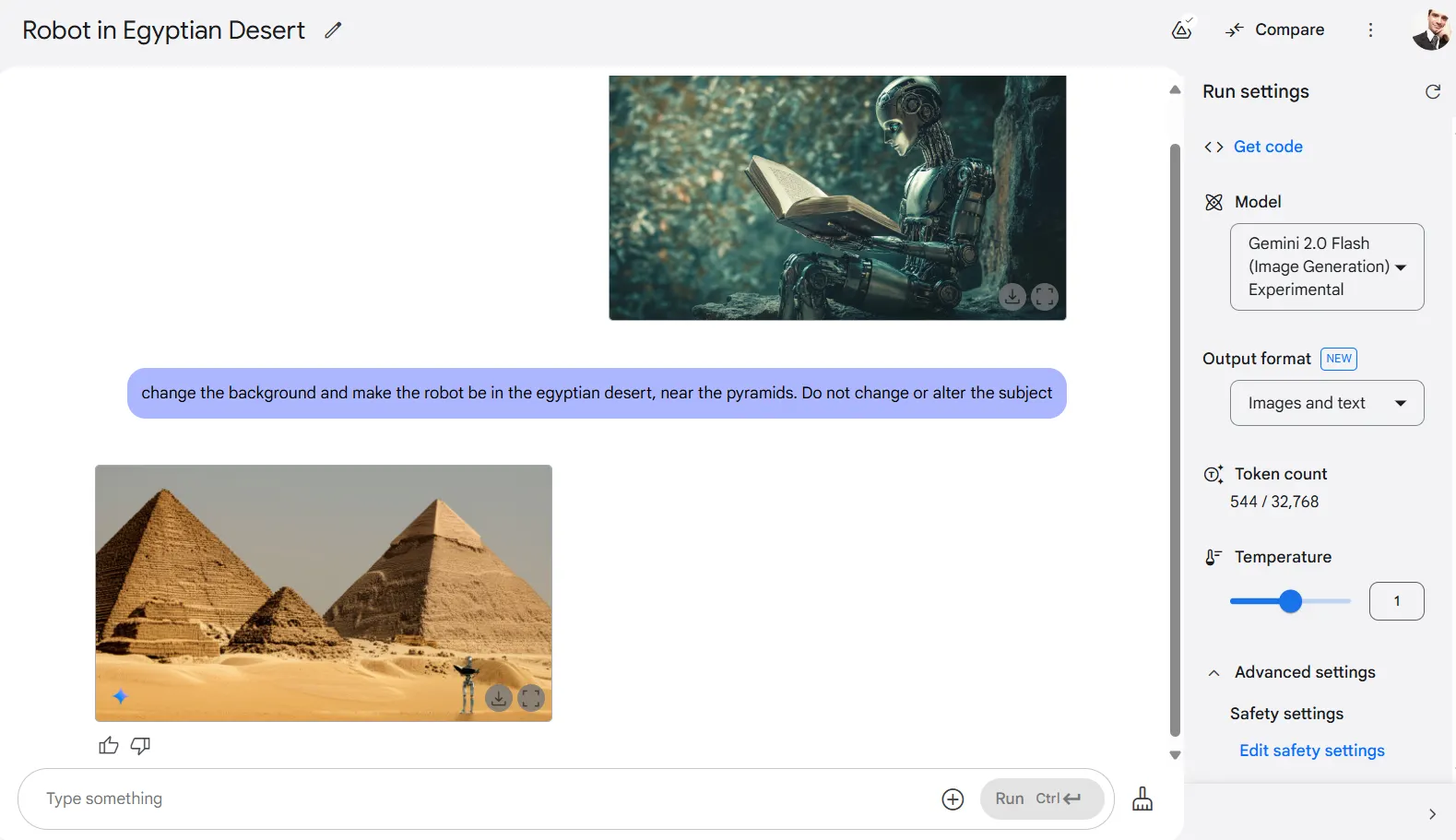
It is usually necessary to have correct phrasing when asking the mannequin to cope with backgrounds. Often it tends to change the entire image, making the composition look completely totally different.
For instance, in a single take a look at, we requested Gemini to modified the background of a photograph, making a sitting robotic be in Egypt as a substitute of its authentic locale. We requested Gemini to not alter the topic. Nonetheless, the mannequin was not in a position to deal with this particular activity correctly, and as a substitute supplied a model new composition that includes the pyramids, with a robotic standing however not as the first topic.
One other fault we discovered is that the mannequin is able to iterating a number of instances with one picture, however the high quality of the main points will lower the extra iterations it goes by way of. So it’s necessary to remember the fact that there could also be a noticeable degradation in high quality should you go too overboard with the edits.

The experimental mannequin is now accessible to builders by way of Google AI Studio and the Gemini API throughout all supported areas. It’s additionally accessible on Hugging Face for customers who are usually not snug with sending their data to Google.
General this appears a kind of hidden gems from Google, very like NotebookLM. It does one thing different fashions can’t do and is nice sufficient at it, however nonetheless not lots of people speak about it. It’s positively well worth the attempt for customers who need to have enjoyable and see the potential of generative AI in picture modifying.
Typically Clever E-newsletter
A weekly AI journey narrated by Gen, a generative AI mannequin.