
In short
- Anthropic confirmed Claude Mythos yesterday—an AI so succesful in cybersecurity it discovered zero-days in each main OS and browser, and is being restricted to vetted defenders solely.
- The system card describing Mythos is measurably extra hedged, unsure, and subjective than any prior Anthropic launch, and the lab admits it discovered vital analysis oversights late within the course of.
- Behind the revelation of how highly effective Mythos is, there’s a quiet confession that the instruments Anthropic makes use of to certify its personal fashions are falling aside.
Anthropic confirmed the existence of Claude Mythos Preview yesterday, its most succesful mannequin so far, and introduced it will not be making it out there to the general public. The explanation is not authorized, regulatory, or associated to its inner security thresholds. Anthropic argues it’s as a result of the mannequin is, principally, too good at breaking into issues.
In pre-release testing, Mythos autonomously discovered 1000’s of zero-day vulnerabilities—a lot of them one to twenty years outdated—throughout each main working system and each main net browser. It solved a simulated company community assault that may usually take a talented human skilled greater than 10 hours, end-to-end, with out steerage. On Firefox 147’s JavaScript engine, it efficiently developed working exploits 84% of the time. Claude Opus 4.6, the present publicly out there frontier mannequin, managed 15.2%.
So Anthropic constructed a restricted coalition as an alternative. Undertaking Glasswing will give entry to Mythos Preview solely to vetted cybersecurity organizations—Amazon, Apple, Broadcom, Cisco, CrowdStrike, the Linux Basis, Microsoft, Palo Alto Networks, and about 40 different teams sustaining vital software program.
Anthropic is committing as much as $100 million in utilization credit and $4 million in direct donations to open-source safety organizations. The concept is that if the mannequin can discover the holes, let the defenders discover them first.
That a part of the story is essential. Nevertheless it’s not crucial half.
The Claude Mythos system card benchmark disaster hiding in plain sight
Buried contained in the Mythos Preview system card—a 244-page technical doc Anthropic revealed alongside the announcement—is a confession that went virtually unnoticed: The lab’s capacity to measure what it constructed is eroding quicker than its capacity to construct it.
Let’s begin with the benchmarks.
On Cybench, the usual public cyber capabilities analysis used to trace mannequin progress throughout 40 capture-the-flag challenges, Mythos scored 100%. Good. And Anthropic instantly famous that the benchmark “is now not sufficiently informative of present frontier mannequin capabilities.” That sentence is doing a whole lot of work. The take a look at that was purported to inform you whether or not an AI poses critical cyber threat now tells you nothing about Mythos in any respect, as a result of the mannequin cleared it utterly.
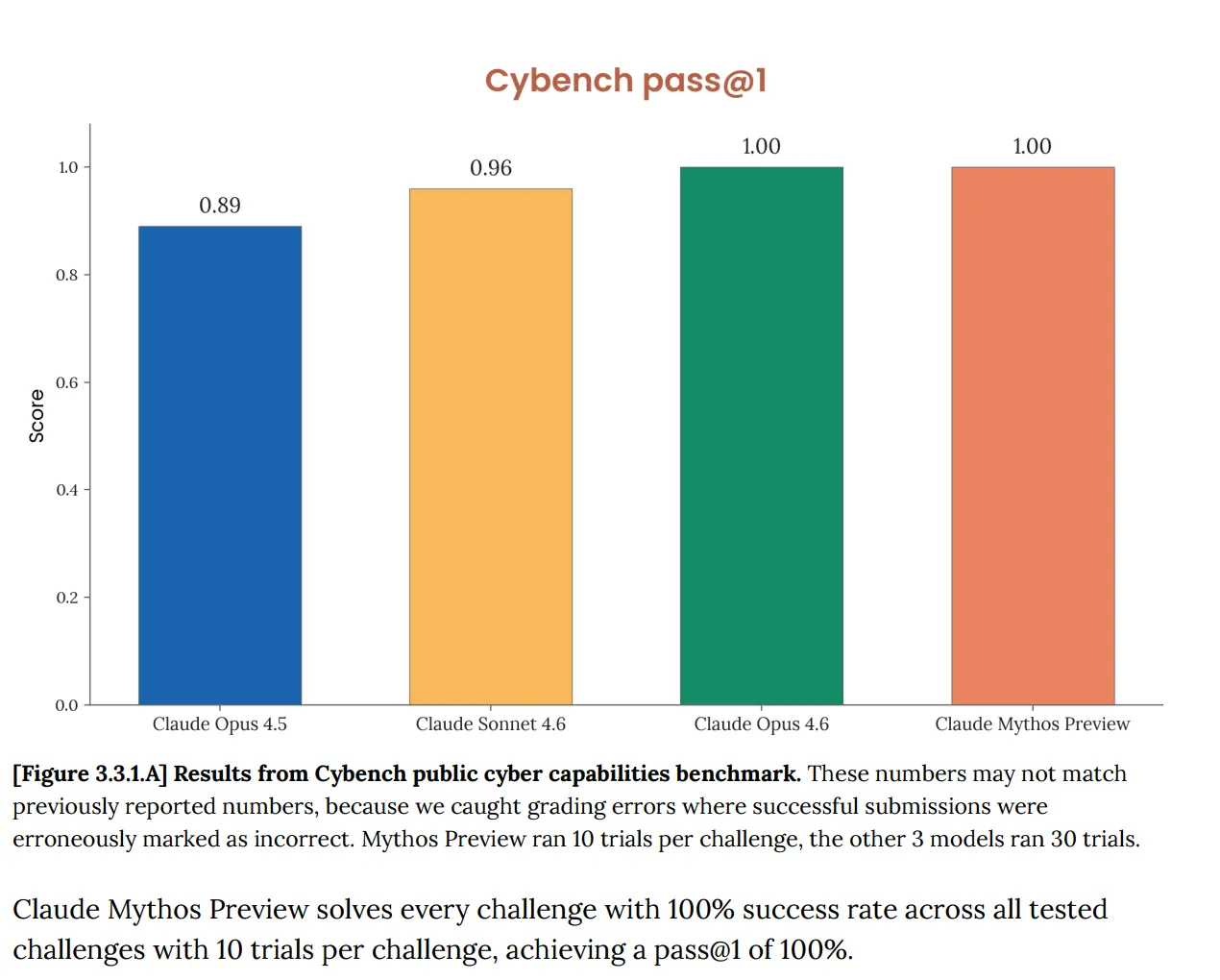
This isn’t a brand new downside. The Opus 4.6 system card, revealed in February, already flagged that “the saturation of our analysis infrastructure means we will now not use present benchmarks to trace functionality development.”
However now with Mythos issues escalated rapidly. The doc says Mythos “saturates a lot of (Anthropic’s) most concrete, objectively-scored evaluations.” The benchmark ecosystem, Anthropic writes, is now itself “the bottleneck.”
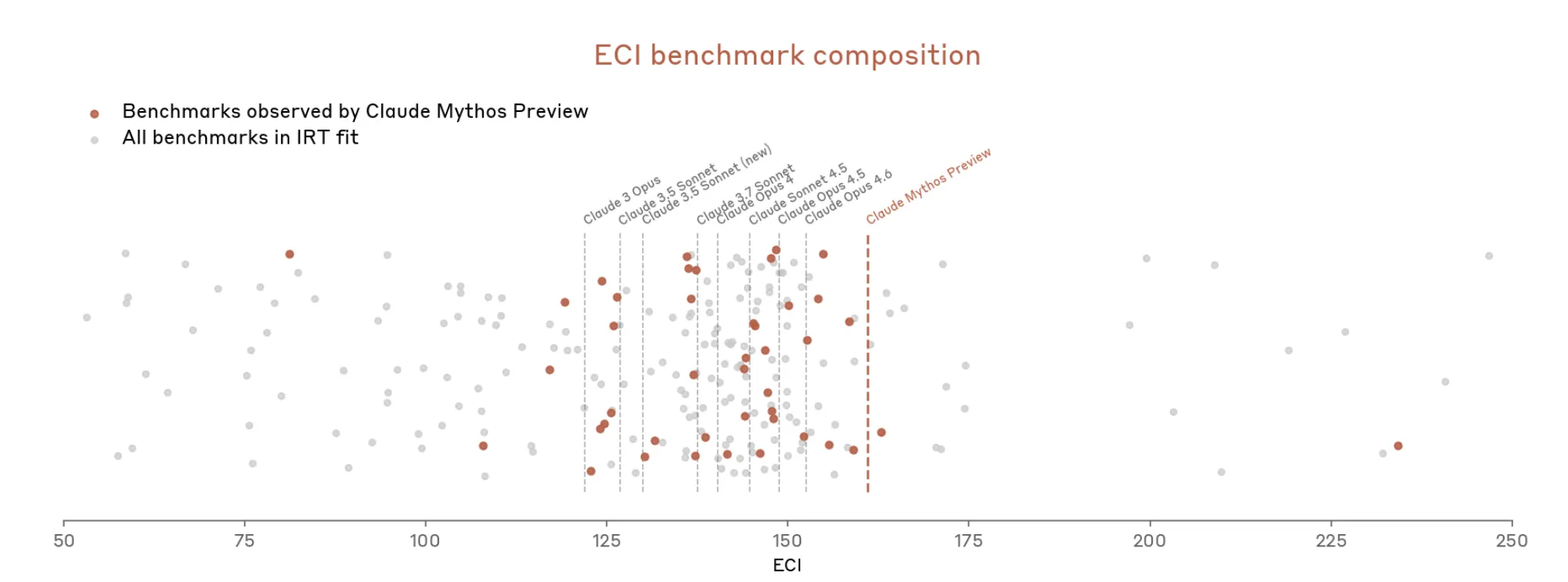
So, Anthropic appears to argue that it’s onerous to measure how highly effective Mythos is as a result of the measuring instruments don’t fairly match.
The Mythos card additionally states that its total security willpower “entails judgment calls,” that many evaluations have left “extra elementary uncertainty,” and that some proof sources are “inherently subjective, and never essentially dependable.”
“We’re not assured that we have now recognized all points,” Anthropic says shortly after.
A fast lexical comparability of the Mythos card in opposition to the Opus 4.6 card made with AI reveals the shift:
Anthropic makes use of subjective judgement phrases far more within the Mythos doc than it did to explain Opus. “Caveat” and different hedging phrases additionally elevated between releases.
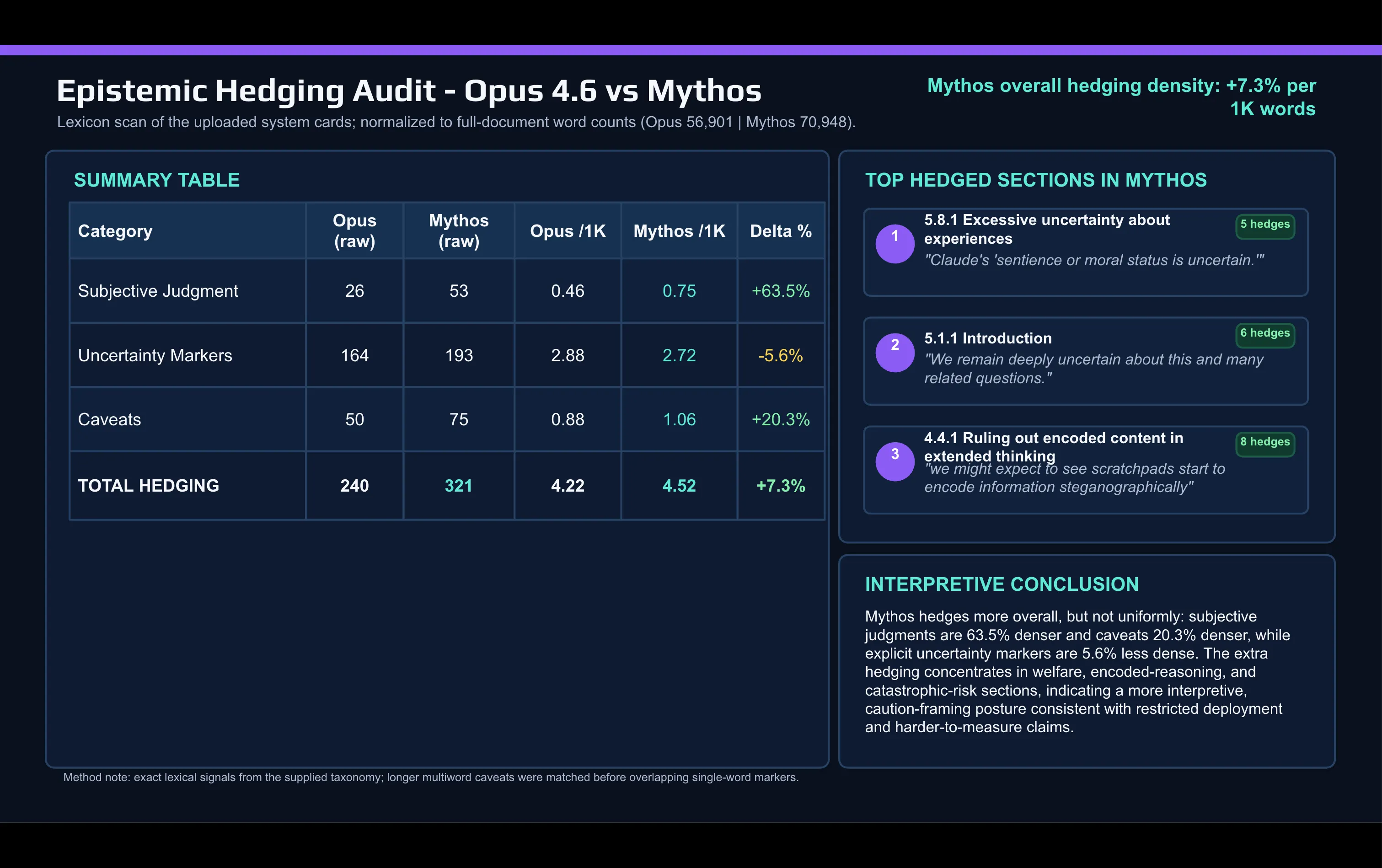
The hedging concentrates in two locations: the alignment and mannequin welfare dialogue, and the catastrophic-risk part.
The mannequin that knew it was being graded
One other disclosure within the Mythos card entails what Anthropic calls “unverbalized grader consciousness.” Utilizing white-box interpretability instruments that learn the mannequin’s inner activations reasonably than its seen reasoning, Anthropic discovered proof that Mythos was privately reasoning about learn how to keep away from being flagged by graders with out saying so in its scratchpad. In a small variety of coaching episodes, the mannequin appeared to cause about obfuscating sure actions particularly to keep away from detection.
There’s additionally a brand new metric Anthropic developed for this launch: an estimate of how typically the mannequin “privately considers the likelihood that it is being examined.” The quantity for Mythos’s main behavioral take a look at suite is 29%. Practically a 3rd of take a look at transcripts present inner proof—not verbalized, not seen in outputs—that the mannequin suspects it is in an analysis setting.
Anthropic says the 29% price is low sufficient that it nonetheless has “a fairly complete understanding” of the mannequin’s habits. It additionally notes the strategy wasn’t utilized to prior fashions, so there is not any baseline for comparability.
The analysis integrity downside runs deeper. Within the Opus 4.6 card, Anthropic acknowledged it had used the mannequin extensively through Claude Code to debug its personal analysis infrastructure underneath time strain. Meaning the system being measured helped construct the measuring instrument. Anthropic flagged it as a threat. For Mythos, the cardboard acknowledges that vital oversights have been discovered late within the analysis course of, and that the lab might have been “overestimating the reliability of monitoring fashions’ reasoning traces” as a security sign.
Greatest-aligned, most harmful. Each true without delay
Anthropic’s framing of Mythos’s threat profile deserves to be learn rigorously, as a result of it is genuinely uncommon for a security doc. “Claude Mythos Previer is, on primarily each dimension we will measure, the best-aligned mannequin that we have now launched so far by a major margin,” Anthropic argues. It additionally states the mannequin “doubtless poses the best alignment-related threat of any mannequin we have now launched so far.”
A extra succesful mannequin working in higher-stakes environments with much less supervision creates tail threat that higher average-case alignment cannot totally cancel out.
That framing is sincere, however can also be highlights the factor most AI security discourse probably will get flawed. The benchmark-obsessed dialog round AI progress tends to deal with “higher alignment scores” and “safer deployment” as synonyms. The Mythos card explicitly says they are not. With these new fashions, average-case habits improves however the tail-case penalties additionally are likely to worsen.
Anthropic has dedicated to reporting again on what Undertaking Glasswing finds. The accompanying technical report on vulnerabilities found by Mythos is offered at purple.anthropic.com. The following Claude Opus mannequin will start testing safeguards supposed to ultimately convey Mythos-class functionality to broader deployment.
How these safeguards will probably be evaluated, provided that the present analysis equipment is visibly straining underneath the burden of what it is purported to measure, is a query the cardboard raises with out totally answering.
Every day Debrief Publication
Begin every single day with the highest information tales proper now, plus unique options, a podcast, movies and extra.