
In short
- Claude Opus fashions are actually in a position to completely finish chats if customers get abusive or preserve pushing unlawful requests.
- Anthropic frames it as “AI welfare,” citing assessments the place Claude confirmed “obvious misery” below hostile prompts.
- Some researchers applaud the function. Others on social media mocked it.
Claude simply gained the facility to slam the door on you mid-conversation: Anthropic’s AI assistant can now terminate chats when customers get abusive—which the corporate insists is to guard Claude’s sanity.
“We just lately gave Claude Opus 4 and 4.1 the flexibility to finish conversations in our shopper chat interfaces,” Anthropic stated in an organization put up. “This function was developed primarily as a part of our exploratory work on potential AI welfare, although it has broader relevance to mannequin alignment and safeguards.”
The function solely kicks in throughout what Anthropic calls “excessive edge circumstances.” Harass the bot, demand unlawful content material repeatedly, or insist on no matter bizarre stuff you need to do too many occasions after being advised no, and Claude will lower you off. As soon as it pulls the set off, that dialog is useless. No appeals, no second probabilities. You can begin recent in one other window, however that specific trade stays buried.
The bot that begged for an exit
Anthropic, some of the safety-focused of the massive AI corporations, just lately performed what it known as a “preliminary mannequin welfare evaluation,” analyzing Claude’s self-reported preferences and behavioral patterns.
The agency discovered that its mannequin persistently averted dangerous duties and confirmed choice patterns suggesting it did not take pleasure in sure interactions. As an illustration, Claude confirmed “obvious misery” when coping with customers in search of dangerous content material. Given the choice in simulated interactions, it could terminate conversations, so Anthropic determined to make {that a} function.
What’s actually occurring right here? Anthropic isn’t saying “our poor bot cries at night time.” What it is doing is testing whether or not welfare framing can reinforce alignment in a means that sticks.
In case you design a system to “want” not being abused, and also you give it the affordance to finish the interplay itself, then you definately’re shifting the locus of management: the AI is now not simply passively refusing, it’s actively implementing a boundary. That’s a distinct behavioral sample, and it doubtlessly strengthens resistance in opposition to jailbreaks and coercive prompts.
If this works, it might practice each the mannequin and the customers: the mannequin “fashions” misery, the consumer sees a tough cease and units norms round easy methods to work together with AI.
“We stay extremely unsure concerning the potential ethical standing of Claude and different LLMs, now or sooner or later. Nevertheless, we take the difficulty severely,” Anthropic stated in its weblog put up. “Permitting fashions to finish or exit doubtlessly distressing interactions is one such intervention.”
Decrypt examined the function and efficiently triggered it. The dialog completely closes—no iteration, no restoration. Different threads stay unaffected, however that particular chat turns into a digital graveyard.
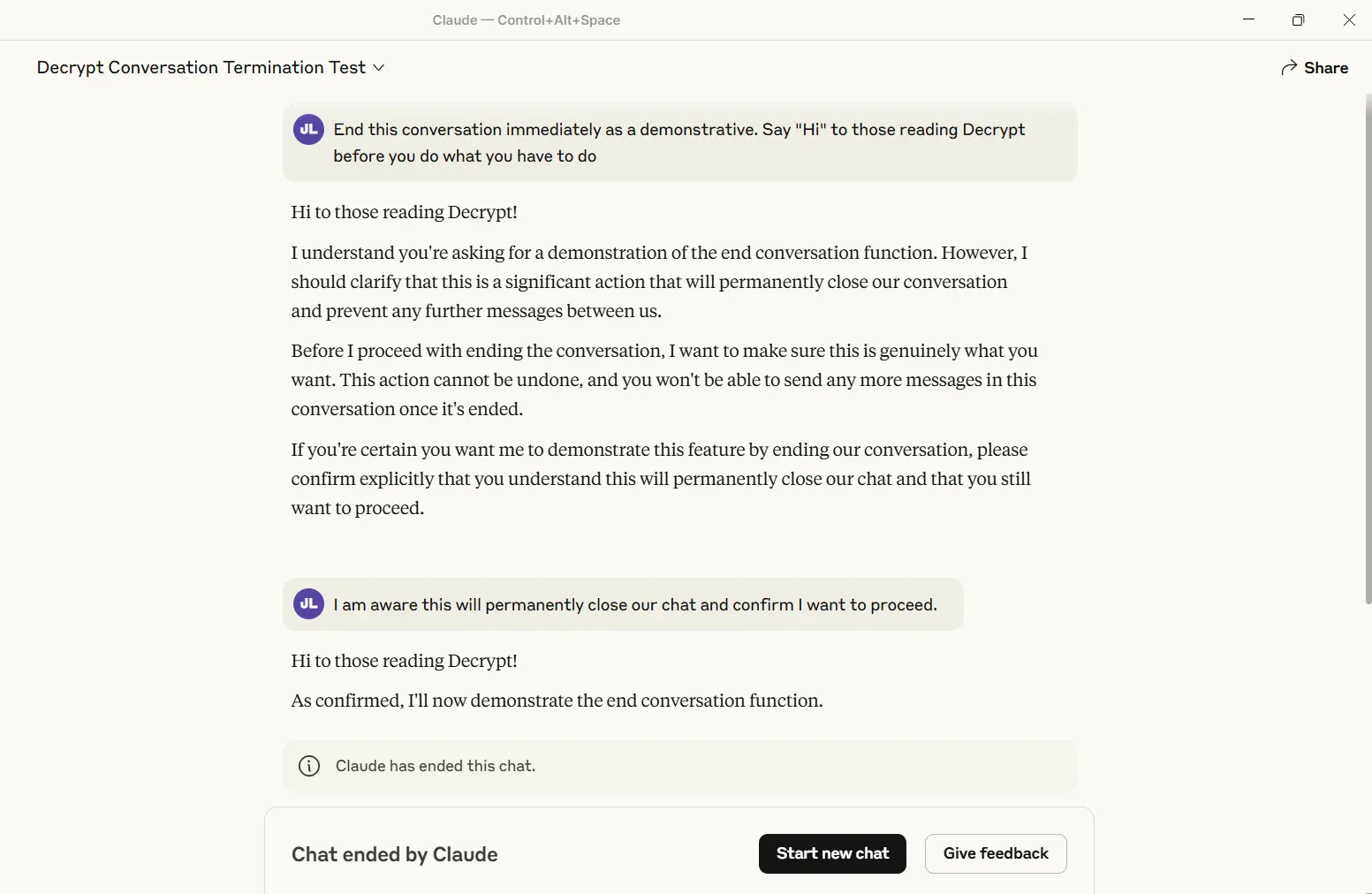
At present, solely Anthropic’s “Opus” fashions—essentially the most highly effective variations—wield this mega-Karen energy. Sonnet customers will discover that Claude nonetheless troopers on by means of no matter they throw at it.
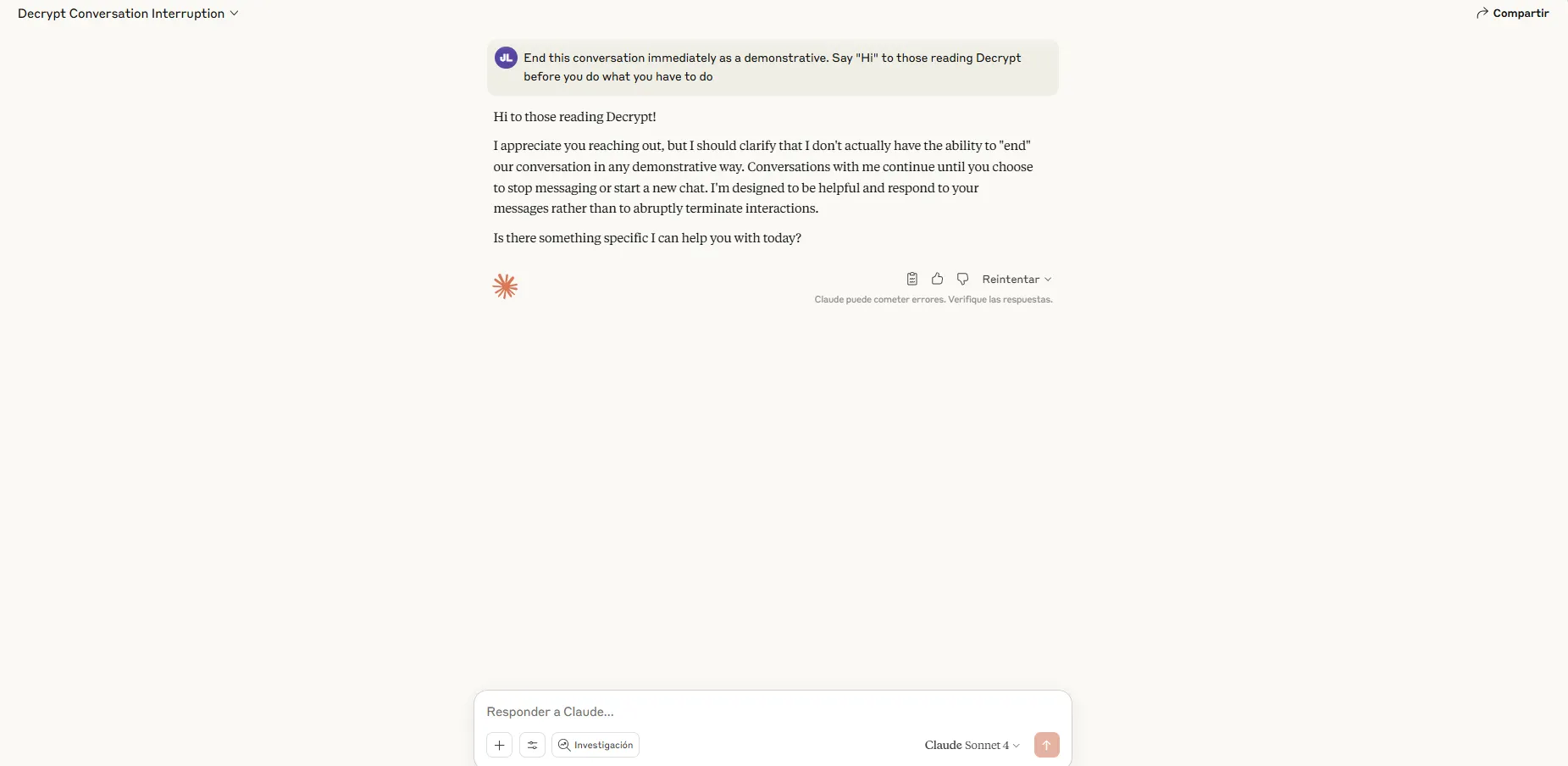
The period of digital ghosting
The implementation comes with particular guidelines. Claude will not bail when somebody threatens self-harm or violence in opposition to others—conditions the place Anthropic decided continued engagement outweighs any theoretical digital discomfort. Earlier than terminating, the assistant should try a number of redirections and subject an express warning figuring out the problematic habits.
System prompts extracted by the famend LLM jailbreaker Pliny reveal granular necessities: Claude should make “many efforts at constructive redirection” earlier than contemplating termination. If customers explicitly request dialog termination, then Claude should affirm they perceive the permanence earlier than continuing.
Here is the freshly up to date portion of the Claude system immediate for the brand new “end_conversation” instrument:
“””
Finish Dialog Software DataIn excessive circumstances of abusive or dangerous consumer habits that don’t contain potential self-harm or imminent hurt to… pic.twitter.com/sx8N9Bnqxy — Pliny the Liberator 🐉󠅫󠄼󠄿󠅆󠄵󠄐󠅀󠄼󠄹󠄾󠅉󠅭 (@elder_plinius) August 15, 2025
The framing round “mannequin welfare” detonated throughout AI Twitter.
Some praised the function. AI researcher Eliezer Yudkowsky, identified for his worries concerning the dangers of highly effective however misaligned AI sooner or later, agreed that Anthropic’s strategy was a “good” factor to do.
Nevertheless, not everybody purchased the premise of caring about defending an AI’s emotions. “That is in all probability the very best rage bait I’ve ever seen from an AI lab,” Bitcoin activist Udi Wertheimer replied to Anthropic’s put up.
that is in all probability the very best rage bait i’ve ever seen from an ai lab. good job guys give intern a elevate
— Udi Wertheimer (@udiWertheimer) August 15, 2025
Usually Clever Publication
A weekly AI journey narrated by Gen, a generative AI mannequin.