
Briefly
- Google stated its TurboQuant algorithm can lower a significant AI reminiscence bottleneck by no less than sixfold with no accuracy loss throughout inference.
- Reminiscence shares together with Micron, Western Digital and Seagate fell after the paper circulated.
- The tactic compresses inference reminiscence, not mannequin weights, and has solely been examined in analysis benchmarks.
Google Analysis revealed TurboQuant on Wednesday, a compression algorithm that shrinks a significant inference-memory bottleneck by no less than 6x whereas sustaining zero loss in accuracy.
The paper is slated for presentation at ICLR 2026, and the response on-line was instant.
Cloudflare CEO Matthew Prince referred to as it Google’s DeepSeek second. Reminiscence inventory costs, together with Micron, Western Digital, and Seagate, fell on the identical day.
So is it actual?
Quantization effectivity is an enormous achievement by itself. However “zero accuracy loss” wants context.
TurboQuant targets the KV cache—the chunk of GPU reminiscence that shops all the things a language mannequin wants to recollect throughout a dialog.
As context home windows develop towards hundreds of thousands of tokens, these caches balloon into a whole lot of gigabytes per session. That is the precise bottleneck. Not compute energy however uncooked reminiscence.
Conventional compression strategies attempt to shrink these caches by rounding numbers down—from 32-bit floats to 16, to eight to 4-bit integers, for instance. To raised perceive it, consider shrinking a picture from 4K, to full HD, to 720p and so. It’s straightforward to inform it’s the identical picture general, however there’s extra element in 4K decision.
The catch: they need to retailer additional “quantization constants” alongside the compressed knowledge to maintain the mannequin from going silly. These constants add 1 to 2 bits per worth, partially eroding the features.
TurboQuant claims it eliminates that overhead fully.
It does this by way of two sub-algorithms. PolarQuant separates magnitude from route in vectors, and QJL (Quantized Johnson-Lindenstrauss) takes the tiny residual error left over and reduces it to a single signal bit, constructive or destructive, with zero saved constants.
The consequence, Google says, is a mathematically unbiased estimator for the eye calculations that drive transformer fashions.
In benchmarks utilizing Gemma and Mistral, TurboQuant matched full-precision efficiency beneath 4x compression, together with good retrieval accuracy on needle-in-haystack duties as much as 104,000 tokens.
For context on why these benchmarks matter, increasing a mannequin’s usable context with out high quality loss has been one of many hardest issues in LLM deployment.
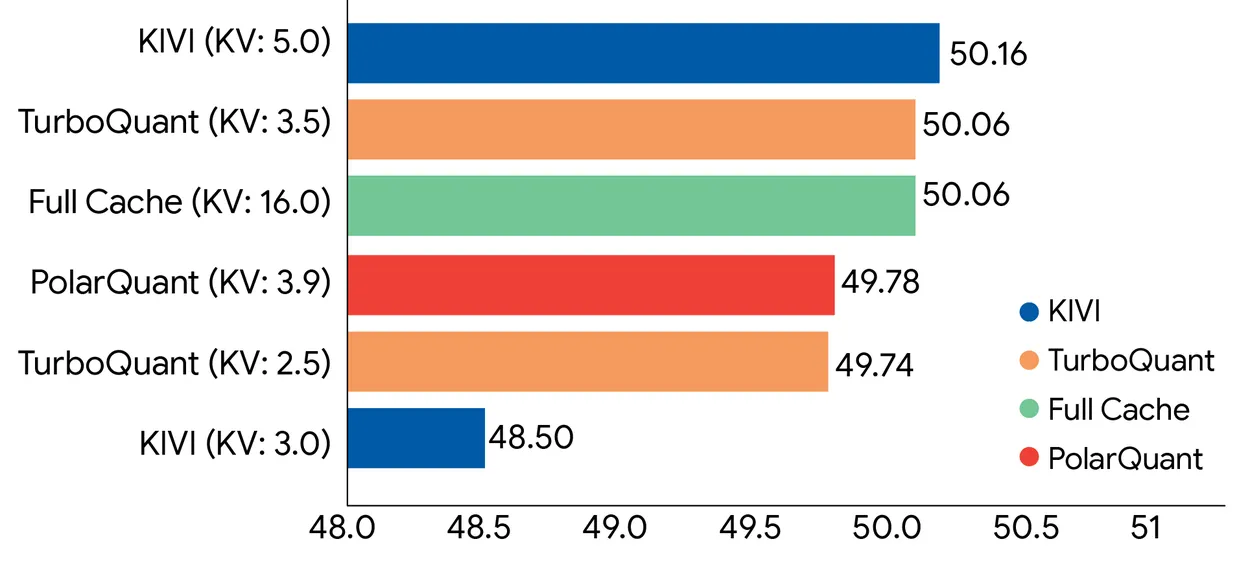
Now, the effective print.
“Zero accuracy loss” applies to KV cache compression throughout inference—to not the mannequin’s weights. Compressing weights is a totally totally different, tougher downside. TurboQuant does not contact these.
What it compresses is the short-term reminiscence storing mid-session consideration computations, which is extra forgiving as a result of that knowledge can theoretically be reconstructed.
There’s additionally the hole between a clear benchmark and a manufacturing system serving billions of requests. TurboQuant was examined on open-source fashions—Gemma, Mistral, Llama—not Google’s personal Gemini stack at scale.
In contrast to DeepSeek’s effectivity features, which required deep architectural selections baked in from the beginning, TurboQuant requires no retraining or fine-tuning and claims negligible runtime overhead. In concept, it drops straight into current inference pipelines.
That is the half that spooked the reminiscence {hardware} sector—as a result of if it really works in manufacturing, each main AI lab runs leaner on the identical GPUs they already personal.
The paper goes to ICLR 2026. Till it ships in manufacturing, the “zero loss” headline stays within the lab.
Day by day Debrief Publication
Begin each day with the highest information tales proper now, plus authentic options, a podcast, movies and extra.