
Briefly
- Alibaba’s Qwen 3.5 Omni brings true real-time omnimodal AI to the frontier race.
- Native audio-visual processing beats stitched multimodal pipelines in pace and coherence.
- Voice cloning, semantic interruption, and vibe coding sign a shift towards absolutely interactive AI brokers.
Alibaba simply dropped its most bold AI improve but.
The corporate’s Qwen group launched Qwen 3.5 Omni on Sunday, a brand new model of its “omnimodal” AI that concurrently processes textual content, photos, audio, and video, and talks again in actual time throughout 36 languages, inserting its mannequin on the identical battlefield as the most recent state-of-the-art AI foundational fashions presently accessible.
1/10 🚀 Qwen3.5-Omni is right here! Scaling as much as a local omni-modal AGI.
Meet the subsequent technology of Qwen, designed for native textual content, picture, audio, and video understanding, with main advances in each intelligence and real-time interplay.
A standout characteristic:
Audio-Visible Vibe… pic.twitter.com/fWWyTl9cPY— Tongyi Lab (@Ali_TongyiLab) March 30, 2026
“Omni” is not only a advertising buzzword right here. Most AI fashions you work together with are primarily text-in, text-out methods. Some deal with photos, some deal with voice. Qwen 3.5 Omni handles all of them natively, on the similar time, with out the necessity to convert all the pieces to textual content by means of third-party instruments.
The brand new mannequin is available in three sizes—Plus, Flash, and Gentle—all supporting a small (by right this moment’s requirements) 256,000-token context window. It was skilled on over 100 million hours of audio-visual knowledge—a scale that places it in a special weight class from most rivals.
Qwen 3.5 Omni is an evolution of Qwen 3 Omni Flash, Alibaba’s earlier omnimodal mannequin launched in December 2025. That model already impressed with its capacity to course of video and audio concurrently—it may deal with picture enhancing directions combining a number of visible inputs in methods rivals could not—and streamed voice responses with latency as little as 234 milliseconds.
It was additionally the primary mannequin to strive an alternative choice to Google’s NotebookLM. It achieved one thing, however the high quality was not on par with Google’s provide.
Qwen 3.5 Omni takes all of that and provides an extended context window, higher reasoning, a a lot wider language library, and a set of real-time interplay options the earlier technology did not have.
The headline improve is what occurs while you really discuss to it. Qwen3.5-Omni now helps semantic interruption: It may well inform the distinction between you saying “uh-huh” mid-sentence and truly wanting to chop in, so it will not cease mid-thought each time somebody coughs within the background, making spoken interplay extra seamless.
A brand new approach known as ARIA, brief for Adaptive Charge Interleave Alignment, additionally fixes a refined however persistent annoyance: AI methods that garble numbers or uncommon phrases when studying aloud. ARIA dynamically syncs textual content and speech to maintain output pure and correct.
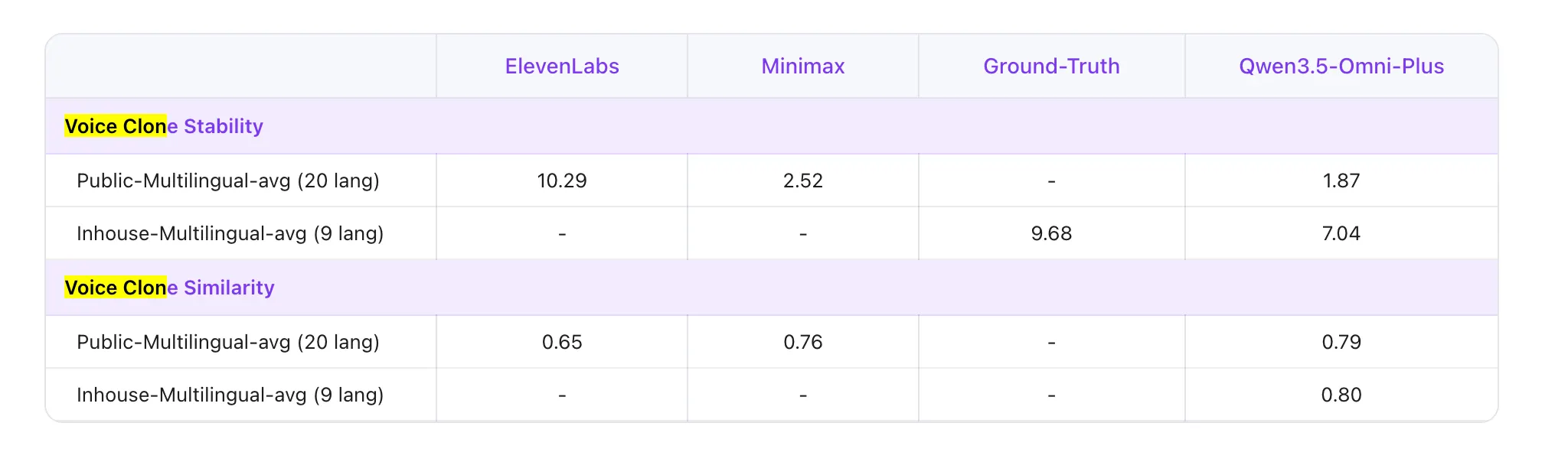
Then there’s voice cloning. Customers can add a voice pattern and have the mannequin undertake that voice in its responses, a characteristic that places Qwen immediately in competitors with ElevenLabs and different devoted voice instruments. We weren’t in a position to entry this characteristic, although, as a result of it is a characteristic that, at the least for now, is just accessible through API..
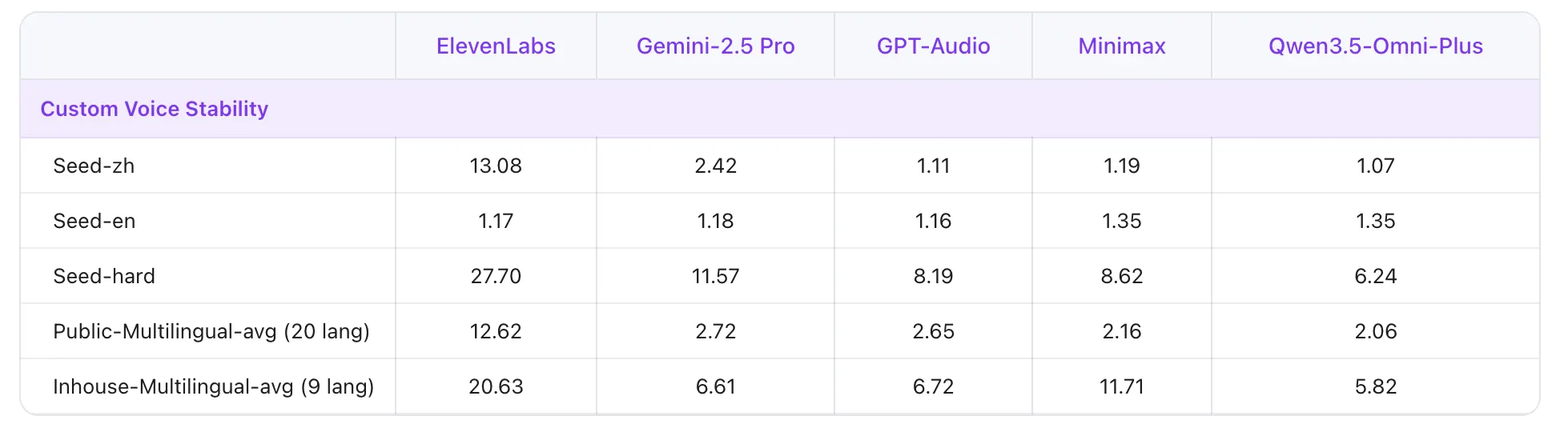
On multilingual voice stability benchmarks, Qwen3.5 Omni- Plus beat ElevenLabs, GPT-Audio, and Minimax throughout 20 languages. The mannequin additionally now helps real-time net search, which means it may reply questions on breaking information or stay market knowledge with out pretending it already is aware of.
The group can be highlighting what they’re calling “Audio-Visible Vibe Coding,” the mannequin can watch a display recording or video of a coding job and write practical code primarily based purely on what it sees and hears, no textual content immediate required. It is a small preview of how AI assistants would possibly finally function inside your workflow reasonably than alongside it.
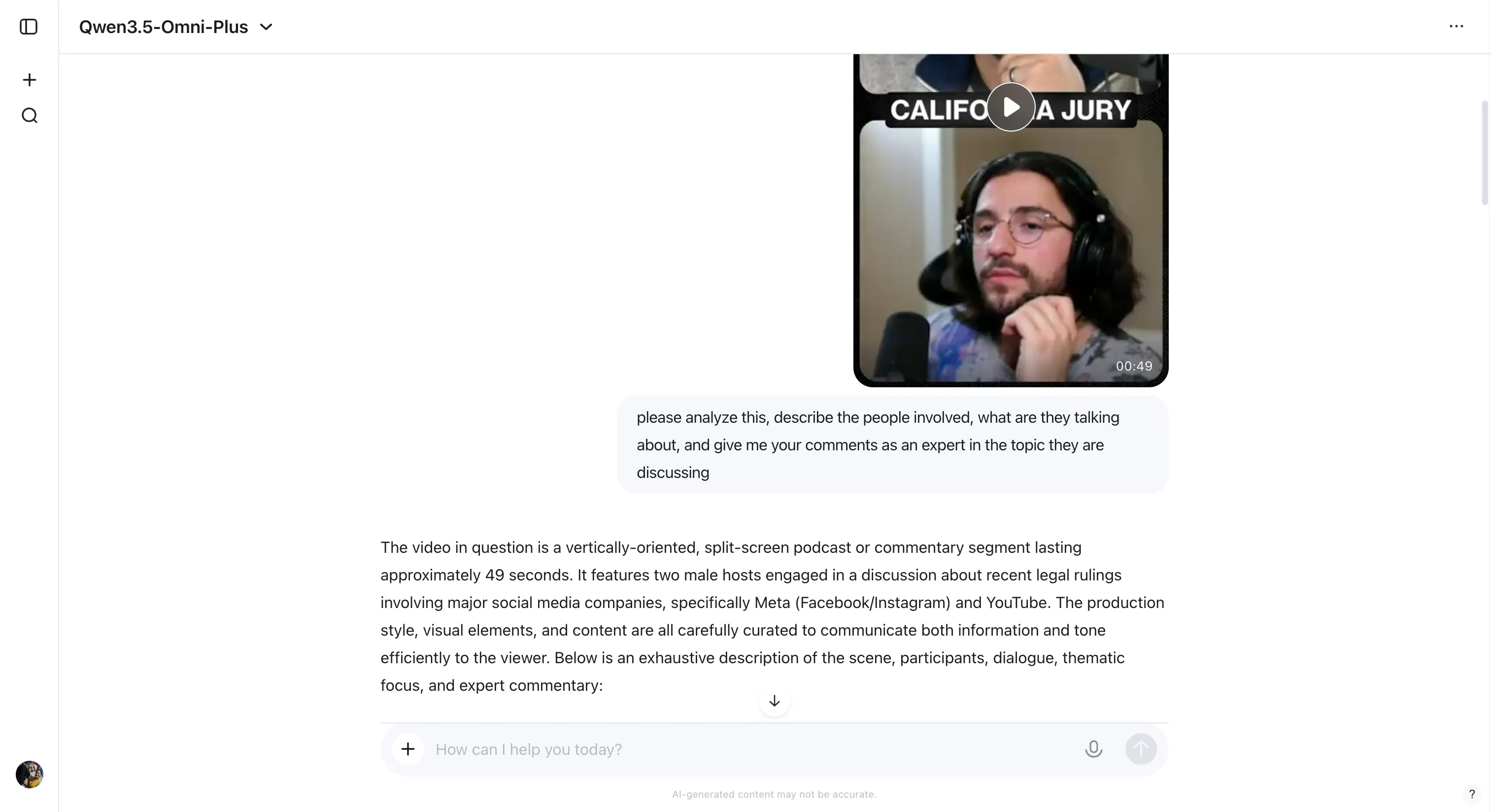
To grasp what “omnimodal” really means in observe, we ran a fast check: We fed each Qwen3.5-Omni and ChatGPT 5.4 in “pondering” mode the identical YouTube Quick—a clip of Dastan President (Dastan is Decrypt’s dad or mum firm) and commentator Farokh discussing breaking information. Qwen 3.5 Omni processed the video natively and returned a full evaluation in about one minute: who was talking, what they have been discussing, and a substantive touch upon the subject primarily based by itself information of the topic space.
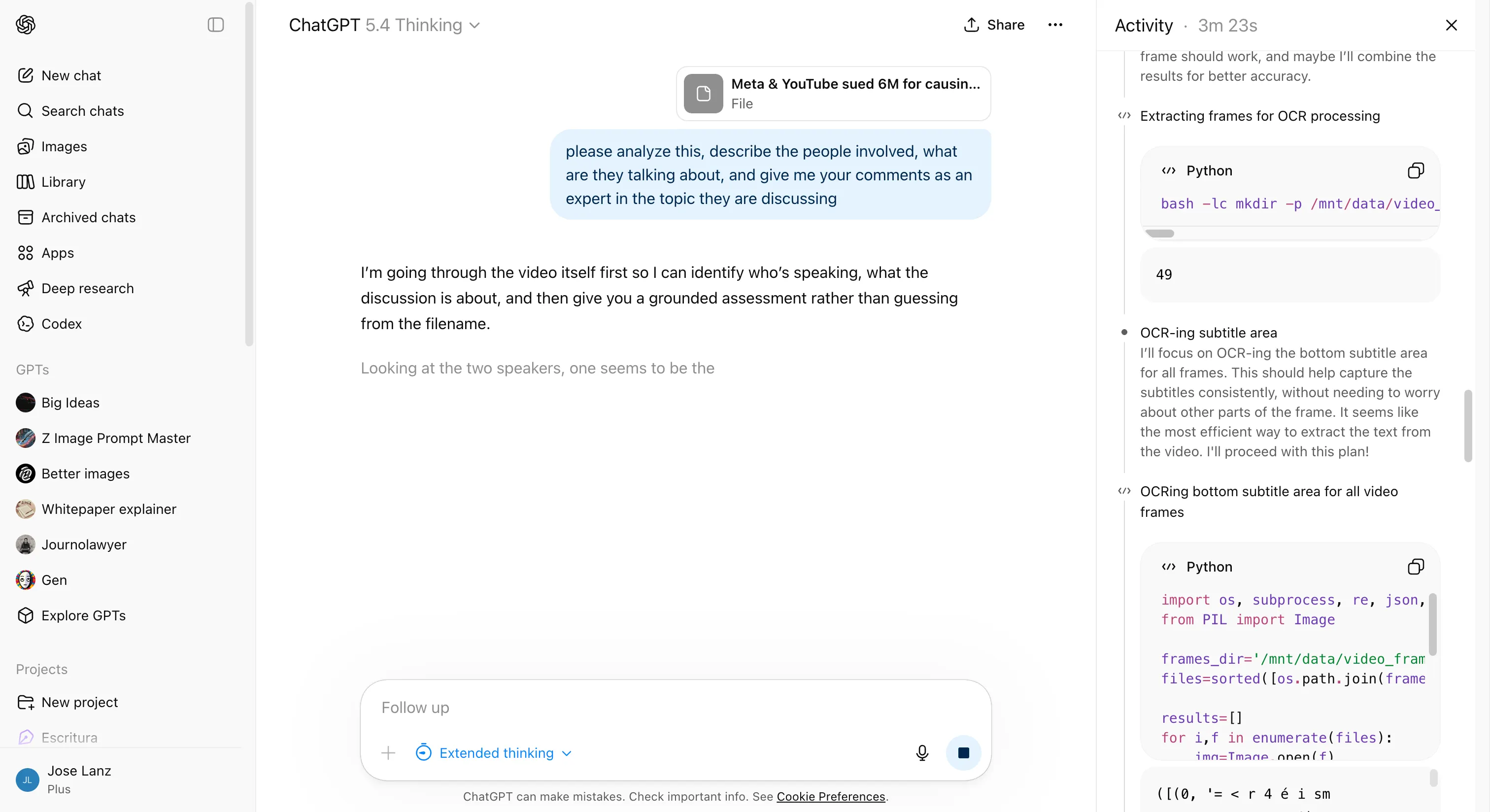
ChatGPT 5.4, which isn’t omnimodal, needed to handle with what it bought. It extracted frames from the video, ran them by means of a imaginative and prescient mannequin, used Whisper to transcribe the audio, and utilized an OCR device to learn embedded subtitles—three separate processes stitched collectively to approximate what Qwen3.5-Omni does in a single go. The end result took 9 minutes, and that is below best situations: a well-lit video with clear audio and burned-in subtitles. Actual-world content material not often affords all three.
In our fast checks throughout a number of inputs, the mannequin additionally dealt with prompts in Spanish, Portuguese, and English with out problem—switching languages mid-conversation with out dropping context.
On normal benchmarks, Qwen 3.5 Omni Plus outperformed Gemini 3.1 Professional on normal audio understanding, reasoning, and translation duties, and matched it on audio-visual comprehension. Speech recognition now covers 113 languages and dialects—up from 19 within the earlier technology.
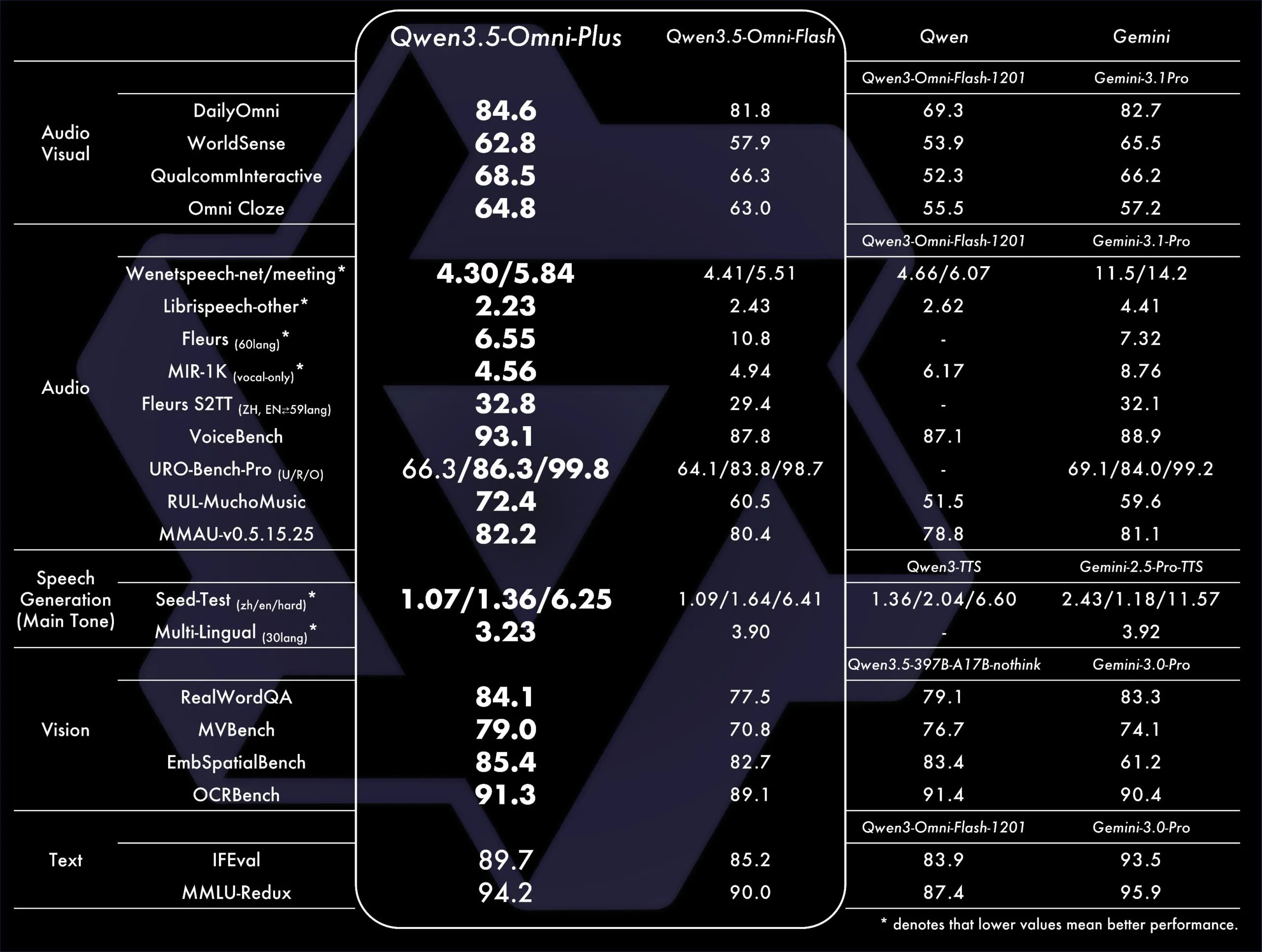
That is Alibaba’s second main AI launch in six weeks. In February, it launched Qwen 3.5, a text-and-vision mannequin that matched or beat frontier fashions on reasoning and coding benchmarks—a part of a streak that has additionally included Qwen Deep Analysis and a lineup of instruments rivaling OpenAI and Google. Qwen 3.5 Omni extends that momentum into full multimodal territory, at a time when each main AI lab is racing to construct methods that deal with the total spectrum of human communication—not simply phrases on a display.
The mannequin is out there now through Alibaba Cloud’s API and will be examined immediately at Qwen Chat or by means of Hugging Face’s on-line demo.
Every day Debrief E-newsletter
Begin on daily basis with the highest information tales proper now, plus authentic options, a podcast, movies and extra.