
When you’ve been following the native AI scene, you in all probability know Qwopus—the open-source mannequin that attempted to distill Claude Opus 4.6’s reasoning into Alibaba’s Qwen, so you may run one thing resembling Opus by yourself {hardware} without cost. It labored surprisingly effectively. The apparent catch: Qwen is a Chinese language mannequin, and never everyone seems to be comfy with that.
Jackrong, the identical pseudonymous developer behind that mission, heard the suggestions. His reply is Gemopus—a brand new household of Claude Opus-style fine-tunes constructed solely on Google’s open-source Gemma 4. All-American DNA, identical thought: frontier-level reasoning, operating regionally on {hardware} you already personal.
The household is available in two flavors. Gemopus-4-26B-A4B is the heavier possibility—a Combination of Consultants mannequin that has 26 billion whole parameters however solely prompts round 4 billion throughout inference, which implies it punches effectively above its weight on constrained {hardware}.
Parameters are what decide an AI’s capability to study, motive, and retailer data. Having 26 billion whole parameters offers the mannequin an enormous breadth of information. However by solely “waking up” the 4 billion parameters related to your particular immediate, it delivers the high-quality outcomes of a large AI whereas remaining light-weight sufficient to run easily on on a regular basis {hardware}.
The opposite is Gemopus-4-E4B, a 4-billion parameter edge mannequin engineered to run comfortably on a contemporary iPhone or a thin-and-light MacBook—no GPU required.
The bottom mannequin alternative issues right here. Google’s Gemma 4, launched on April 2, is constructed instantly from the identical analysis and expertise as Gemini 3—the corporate mentioned so explicitly at launch. Which means Gemopus carries one thing no Qwen-based fine-tune can declare: The DNA of Google’s personal state-of-the-art closed mannequin below the hood, wrapped in Anthropic’s pondering fashion on prime. The most effective of each worlds, kind of.
What makes Gemopus totally different from the wave of different Gemma fine-tunes flooding Hugging Face proper now’s the philosophy behind it. Jackrong intentionally selected to not drive Claude’s chain-of-thought reasoning traces into Gemma’s weights—a shortcut most competing releases take.
His argument, backed by current analysis, is that stuffing a pupil mannequin with a trainer’s surface-level reasoning textual content does not truly switch actual reasoning skill. It teaches imitation, not logic. “There isn’t any want for extreme creativeness or superstitious replication of the Claude-style chain of thought,” the mannequin card reads. As an alternative, he targeted on reply high quality, structural readability, and conversational naturalness—fixing Gemma’s stiff Wikipedia tone and its tendency to lecture you about belongings you did not ask.
AI infrastructure engineer Kyle Hessling ran impartial benchmarks and revealed the outcomes instantly on the mannequin card. His verdict on the 26B variant was fairly favorable. “Glad to have benched this one fairly exhausting and it is a superb finetune of an already distinctive mannequin,” he wrote on X. “It rocks at one-shot requests over lengthy contexts, and runs extremely quick because of the MOE (combination of consultants) structure.”
Gemopus-4-26B-A4B from Jackrong is LIVE!
Glad to have benched this one fairly exhausting (see my benches within the mannequin card) and it is a superb finetune of an already distinctive mannequin! My good friend Jackrong is at all times cooking the best!
It rocks at one-shot requests over lengthy…
— Kyle Hessling (@KyleHessling1) April 10, 2026
The smaller E4B variant handed all 14 core competence assessments—instruction following, coding, math, multi-step reasoning, translation, security, caching—and cleared all 12 long-context assessments at 30K and 60K tokens. On needle-in-haystack retrieval, it handed 13 out of 13 probes together with a stretch take a look at at a million tokens with YaRN 8× RoPE scaling.
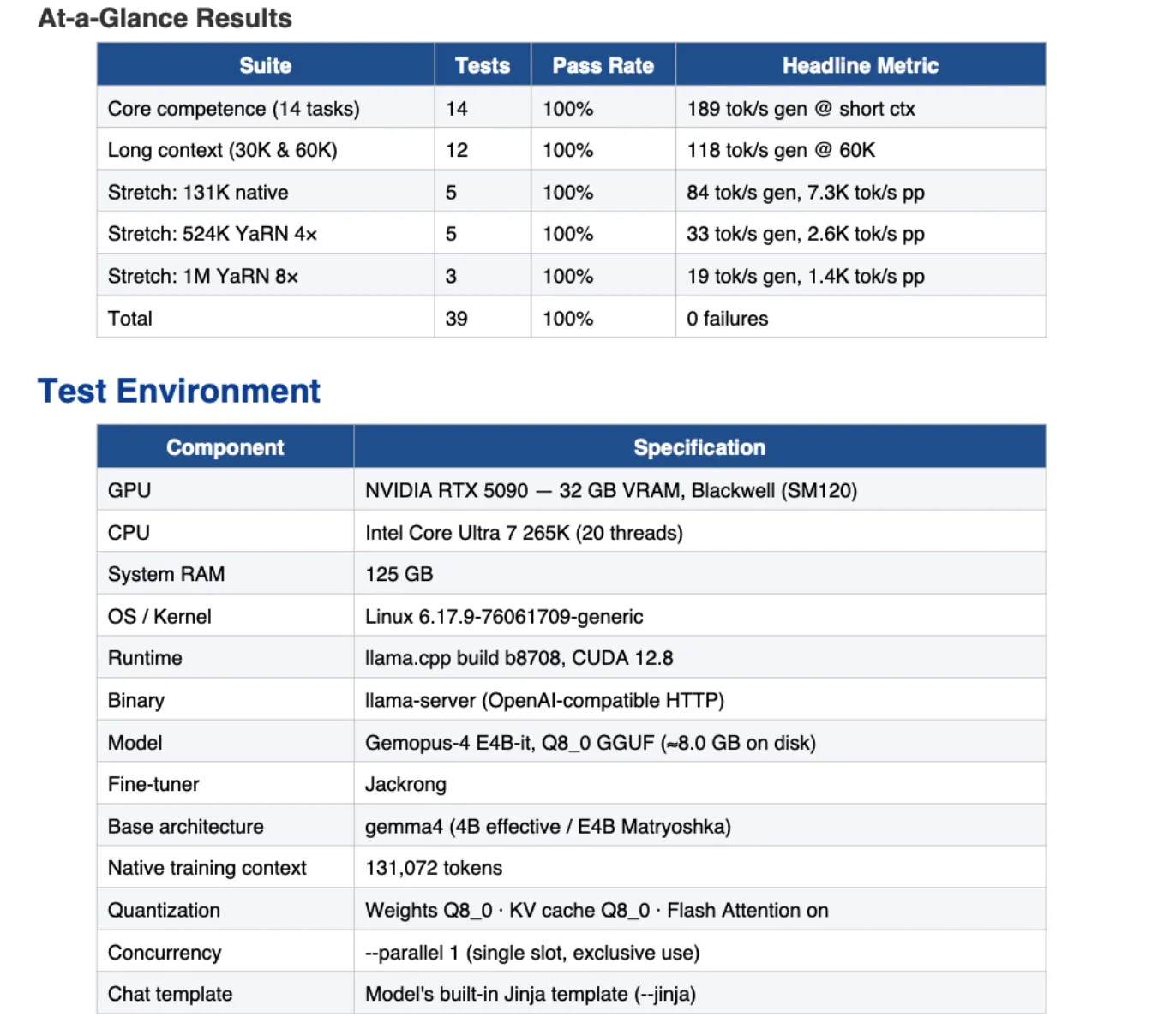
The 26B extends natively to 131K context and all the best way out to 524K with YaRN, which Hessling additionally stress-tested: “It additionally crushed my easy needle-in-the-haystack assessments all the best way out to an prolonged context of 524k!”
On edge {hardware}, the E4B is genuinely quick. Jackrong studies 45–60 tokens per second on iPhone 17 Professional Max, and 90–120 tokens per second on MacBook Air M3/M4 through MLX. The 26B MoE structure means it offloads gracefully on unified reminiscence techniques or GPUs with below 10GB of VRAM. Hessling referred to as it his day by day driver suggestion for VRAM-starved setups.
Each fashions can be found in GGUF format, which implies you may drop them straight into LM Studio or llama.cpp with out configuration. The total coaching code and a step-by-step fine-tuning information are on Jackrong’s GitHub—identical pipeline he used for Qwopus, identical Unsloth and LoRA setup, reproducible on Colab.
Gemopus is just not with out its tough edges. Instrument calling stays damaged throughout the complete Gemma 4 collection in llama.cpp and LM Studio—name failures, format mismatches, loops—so in case your workflow depends upon brokers utilizing exterior instruments, this isn’t your mannequin but. Jackrong himself calls it “an engineering exploration reference fairly than a completely production-ready resolution,” and recommends his personal Qwopus 3.5 collection for anybody who wants one thing extra steady for actual workloads.
And since Jackrong intentionally averted aggressive Claude-style chain-of-thought distillation, do not count on it to really feel as deeply Opus-brained as Qwopus—that was a acutely aware tradeoff for stability, not an oversight.
Yeah the philosophy on this one was stability first, it’s my understanding that the Gemma fashions are inclined to develop into unstable should you drive a bunch of Claude pondering traces into them, you may see this when testing many different Opus gemma superb tunes on hugging face.
Jackrong tried a…
— Kyle Hessling (@KyleHessling1) April 10, 2026
For individuals who need to go deeper into Gemma fine-tuning for reasoning particularly, there’s additionally a separate neighborhood mission price watching: Ornstein by pseudonmyous developer DJLougen, which takes the identical 26B Gemma 4 base and focuses particularly on enhancing its reasoning chains with out counting on the logic or fashion of any particular third social gathering mannequin.
One trustworthy caveat: Gemma’s coaching dynamics are messier than Qwen’s for fine-tuners—wider loss fluctuations, extra hyperparameter sensitivity. Jackrong says so himself. When you want a extra battle-tested native mannequin for manufacturing workflows, his Qwopus 3.5 collection stays extra robustly validated. However if you would like an American mannequin with Opus-style polish, Gemopus is at the moment your greatest accessible possibility. A denser 31B Gemopus variant can be within the pipeline, with Hessling teasing it as “a banger for certain.”
If you wish to attempt operating native fashions by yourself {hardware}, verify our information on easy methods to get began with native AI.
Every day Debrief E-newsletter
Begin day-after-day with the highest information tales proper now, plus unique options, a podcast, movies and extra.