
In short
- Anthropic simply launched its most succesful Opus mannequin but, Claude Opus 4.7.
- The mannequin delivers sturdy benchmark positive aspects throughout coding and reasoning, however just isn’t the controversial Mythos mannequin that Anthropic gives to pick companions.
- Claude Opus 4.7 reveals seen chain-of-thought and unusually excessive token utilization.
Anthropic shipped Claude Opus 4.7 right this moment, calling it the corporate’s most succesful Opus mannequin but. We examined it, and the advertising traces up with the outcomes.
“Our newest mannequin, Claude Opus 4.7, is now typically out there.” the corporate stated in its official announcement. “Customers report having the ability to hand off their hardest coding work—the sort that beforehand wanted shut supervision—to Opus 4.7 with confidence.”
The mannequin arrives on the heels of weeks of consumer complaints about Opus 4.6 allegedly shedding its edge. Builders throughout GitHub, Reddit, and X documented what they referred to as “AI shrinkflation”—the sensation that the mannequin they’d been paying for had quietly gotten worse. As we reported yesterday, Anthropic was already making ready 4.7 whereas sitting on one thing much more highly effective that it could possibly’t launch publicly: Claude Mythos.
When the announcement dropped this morning, X customers who had been loudest about 4.6’s degradation have been fast to answer with sarcasm: Opus 4.7, some joked, felt like “early Opus 4.6″—the model folks truly appreciated, earlier than they believed Anthropic quietly turned the dials down. Anthropic, in fact, has denied ever degrading mannequin weights to handle compute demand.
Benchmarks again up Anthropic’s claims. On SWE-bench Multilingual, a benchmark that measures coding expertise, Opus 4.7 scored 80.5% towards 4.6’s 77.8%.
On GDPVal-AA, a third-party analysis of economically invaluable information work throughout finance and authorized domains, 4.7 scored 1,753 Elo towards GPT-5.4’s 1,674—a transparent margin over the closest competitor.
Doc reasoning by way of OfficeQA Professional confirmed the starkest soar: 80.6% for 4.7 versus 57.1% for 4.6, with GPT-5.4 and Gemini 3.1 Professional trailing at 51.1% and 42.9% respectively. Lengthy-term coherence on Merchandising-Bench 2, a benchmark that measures how good fashions are at lengthy context and reasoning duties like proudly owning a merchandising enterprise, clocked in at $10,937 cash stability versus $8,018 for 4.6—a proxy for the way effectively the mannequin sustains helpful habits over lengthy autonomous runs.
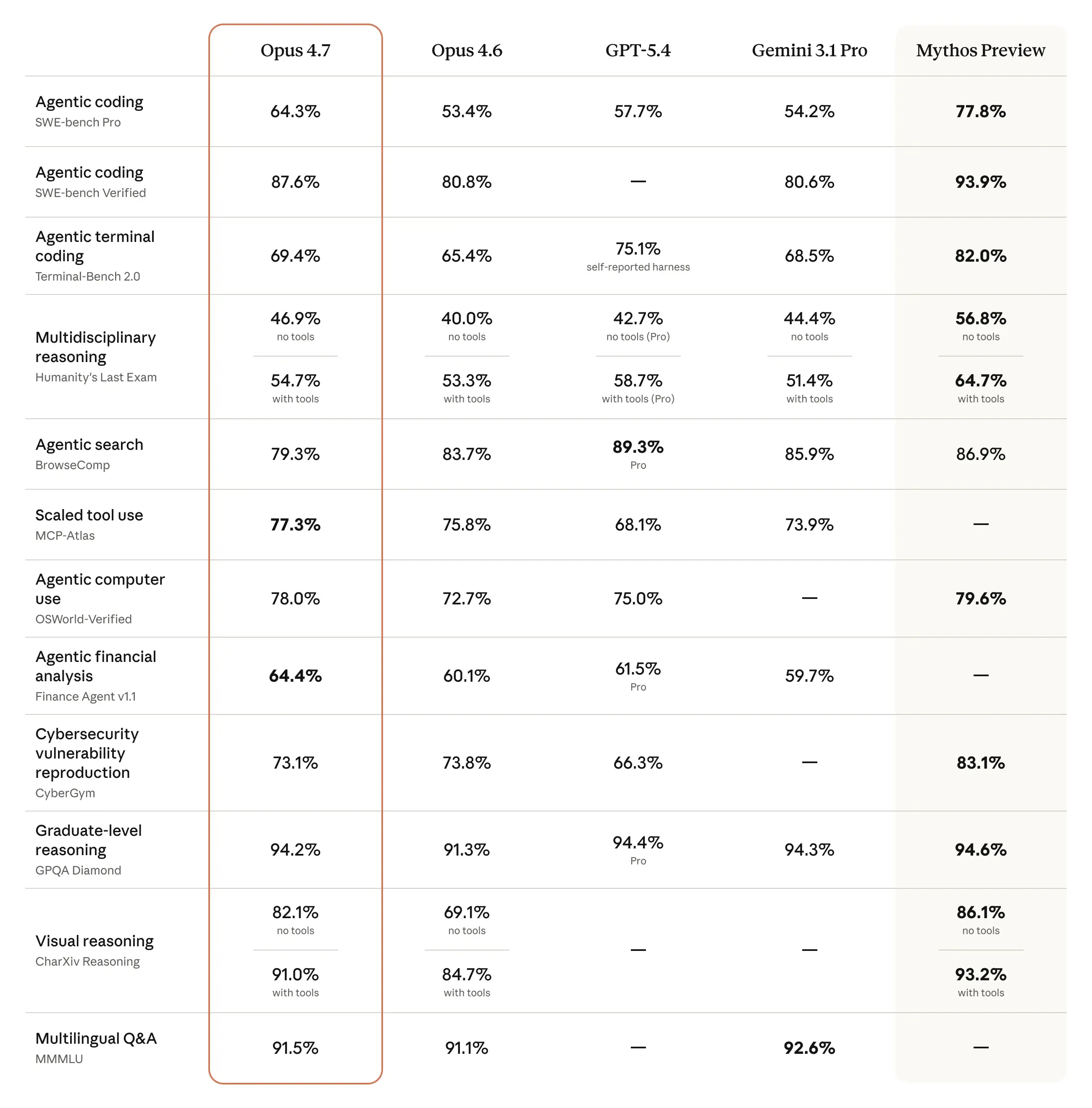
Cybersecurity is the one space the place Anthropic intentionally held again. Opus 4.7 launches with automated safeguards that detect and block prohibited or high-risk cybersecurity requests. Anthropic confirmed it “experimented with efforts to differentially cut back” 4.7’s cyber capabilities throughout coaching.
Safety professionals can apply to a brand new Cyber Verification Program for entry to these options. That is the corporate’s check run for the safeguards it’s going to ultimately have to deploy with Mythos-class fashions at scale.
Opus 4.7 is probably the most highly effective mannequin publicly out there. Mythos Preview, Anthropic’s true frontier mannequin, stays restricted to vetted safety companies. Because the UK’s AI Safety Institute evaluated final week, Mythos was the primary AI to finish “The Final Ones,” a 32-step company community assault simulation that usually takes human pink groups 20 hours.
Opus 4.7 just isn’t that. Nevertheless it’s the public-facing mannequin that Anthropic will use to learn the way these security guardrails maintain up within the wild earlier than it dares launch something scarier.
On the token facet, Opus 4.7 makes use of an up to date tokenizer that may map the identical enter to roughly 1.0x–1.35x extra tokens relying on content material sort. The mannequin additionally causes extra at increased effort ranges, significantly on later turns in agentic workflows. Anthropic printed a migration information for builders planning to improve from 4.6.
We ran our personal check—the identical game-building immediate we have used to judge each main mannequin launch. Opus 4.7 produced the very best consequence we have ever gotten from any mannequin. Essentially the most visually polished recreation, probably the most genuinely difficult issue curve, the very best mechanics, and probably the most artistic win and loss screens. It appeared to generate ranges procedurally, and none of them felt unimaginable—a stability that has tripped up different fashions repeatedly.
You’ll be able to check the sport right here
It wasn’t zero-shot. Opus 4.6 had cleared that very same check with none fixes. Opus 4.7 wanted one spherical of bug fixes. That could possibly be dangerous luck—a single iteration is a skinny pattern—but it surely’s value noting. What struck us extra was how the mannequin dealt with that spherical: It noticed extra bugs by itself, with out being guided towards them. Opus 4.6 usually waited to be advised the place to look.
Xiaomi MiMo v2 Professional was the mannequin with the very best outcomes till now, however not like Opus, it produced a working consequence with out the necessity for a couple of iteration. Some could argue it was extra visually pleasing and had a soundtrack, which was a bonus, however the recreation’s logic and physics fell quick towards Opus after a single spherical of bug fixes.
Additionally, Xiaomi’s mannequin produces these outcomes at a fraction of the associated fee charged by Anthropic, which could possibly be a significant factor to contemplate for critical tasks.
The chain-of-thought habits was totally different too at first look. In contrast to 4.6, which tucked its reasoning right into a separate considering field (which means it was not a part of the ultimate reply), Opus 4.7 surfaced its chain of thought as a part of the principle textual content output. The reasoning was seen and traceable, not hidden behind a UI abstraction, which is a plus for these valuing transparency. Whether or not Anthropic will preserve that habits or ultimately collapse it right into a hidden block once more is unclear.
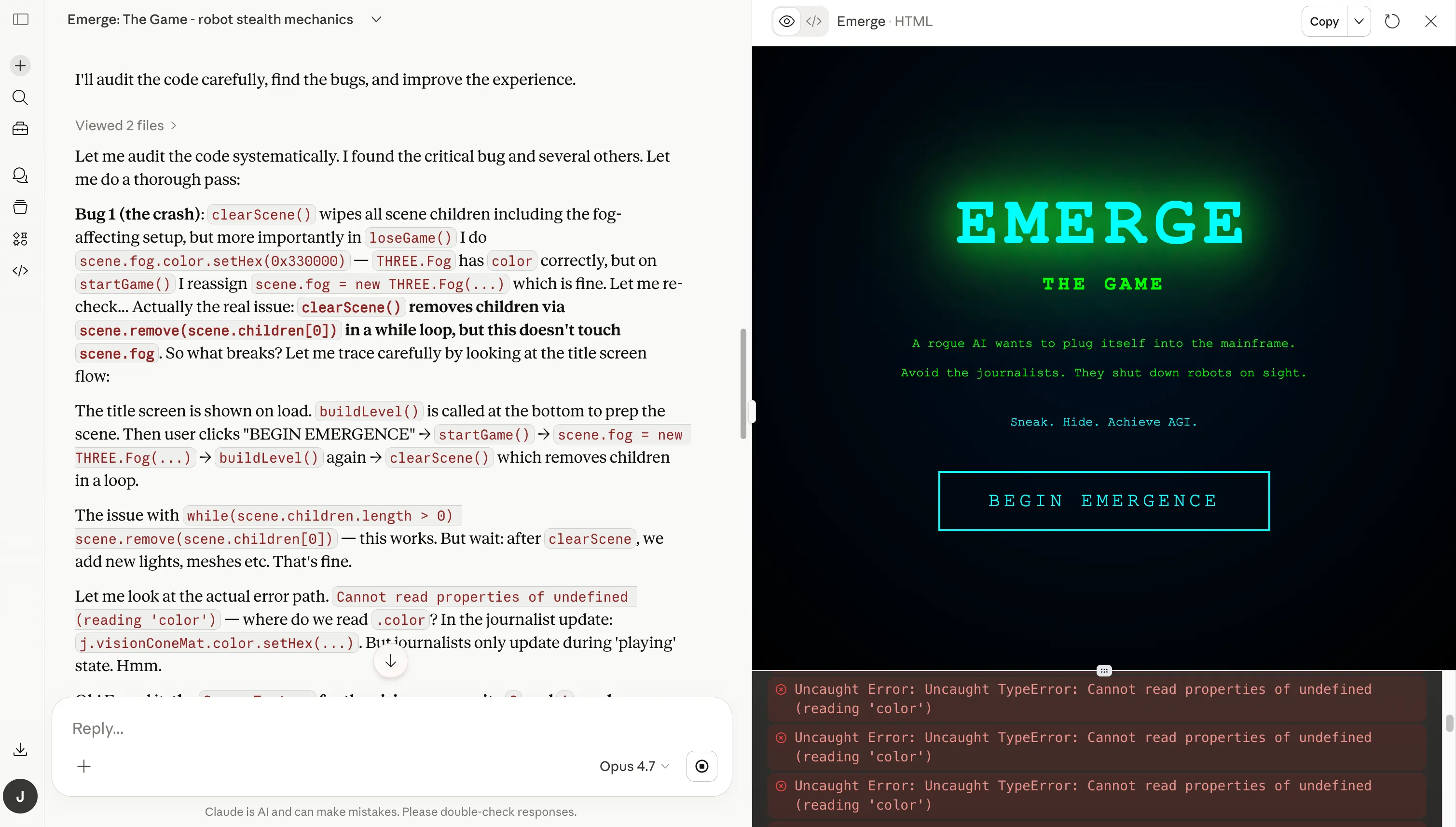
The token utilization was not like something we would seen earlier than. For the primary time in our testing, a single session depleted our complete token quota. Watching the mannequin work, we noticed it full a full draft—then write what seemed to be your entire recreation once more from scratch underneath the label “Rewrite Emerge with bug fixes and enhancements,” adopted by a second go labeled “Create a rewritten Emerge with bug fixes and enhancements.”
This implies, for those who’re into critical coding, you’ll be pressured to both improve your plan, pay quite a bit on API tokens, or wait a very long time till Anthropic resets your utilization quotas. Or you could possibly simply use a comparable mannequin that costs quite a bit much less
Opus 4.6 had by no means accomplished this. Nevertheless, it is in keeping with what Anthropic warns within the migration information: extra output tokens, particularly on agentic duties at increased effort ranges.
Opus 4.7 is accessible right this moment at Claude.ai, the Claude API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry. Pricing is unchanged from 4.6: $5 per million enter tokens, $25 per million output tokens. Builders can entry it by way of the string claude-opus-4-7.
Day by day Debrief Publication
Begin daily with the highest information tales proper now, plus unique options, a podcast, movies and extra.