
Briefly
- Anthropic launched Claude Opus 4.8 on Thursday, simply six weeks after Opus 4.7.
- The replace comes with good points throughout software program engineering, reasoning, and laptop use benchmarks on the identical $5/$25 per million enter/output token worth.
- Opus 4.8’s alignment scores are actually similar to Claude Mythos Preview, Anthropic’s restricted frontier mannequin, with charges of misleading or misuse-friendly habits considerably decrease than its predecessor.
Six weeks. That is how lengthy it took Anthropic to go from Opus 4.7 to Opus 4.8.
The brand new mannequin is quicker and smarter on benchmark assessments, and ships with a collection of recent options—however the worth did not transfer: It’s $5 per million enter tokens and $25 per million output tokens, identical as earlier than.
There’s additionally a quick mode that runs the identical mannequin at 2.5 instances the velocity for $10 enter and a whopping $50 output per million. Anthropic says that fee is now thrice cheaper than what quick mode value on earlier fashions, which is a pleasant method of claiming it was way more costly earlier than.
SWE-bench Professional might be crucial benchmark to observe and have an concept of how good this mannequin is. It measures whether or not an AI can truly resolve onerous, multi-language software program engineering issues drawn from actual manufacturing codebases—scored as a proportion of issues passing.
On that check, Opus 4.8 hit 69.2%, up from 64.3% for Opus 4.7. OpenAI’s GPT-5.5 scored 58.6%, and Google’s Gemini 3.1 Professional trailed at 54.2%. For a mannequin on the identical worth level, that is a significant leap.
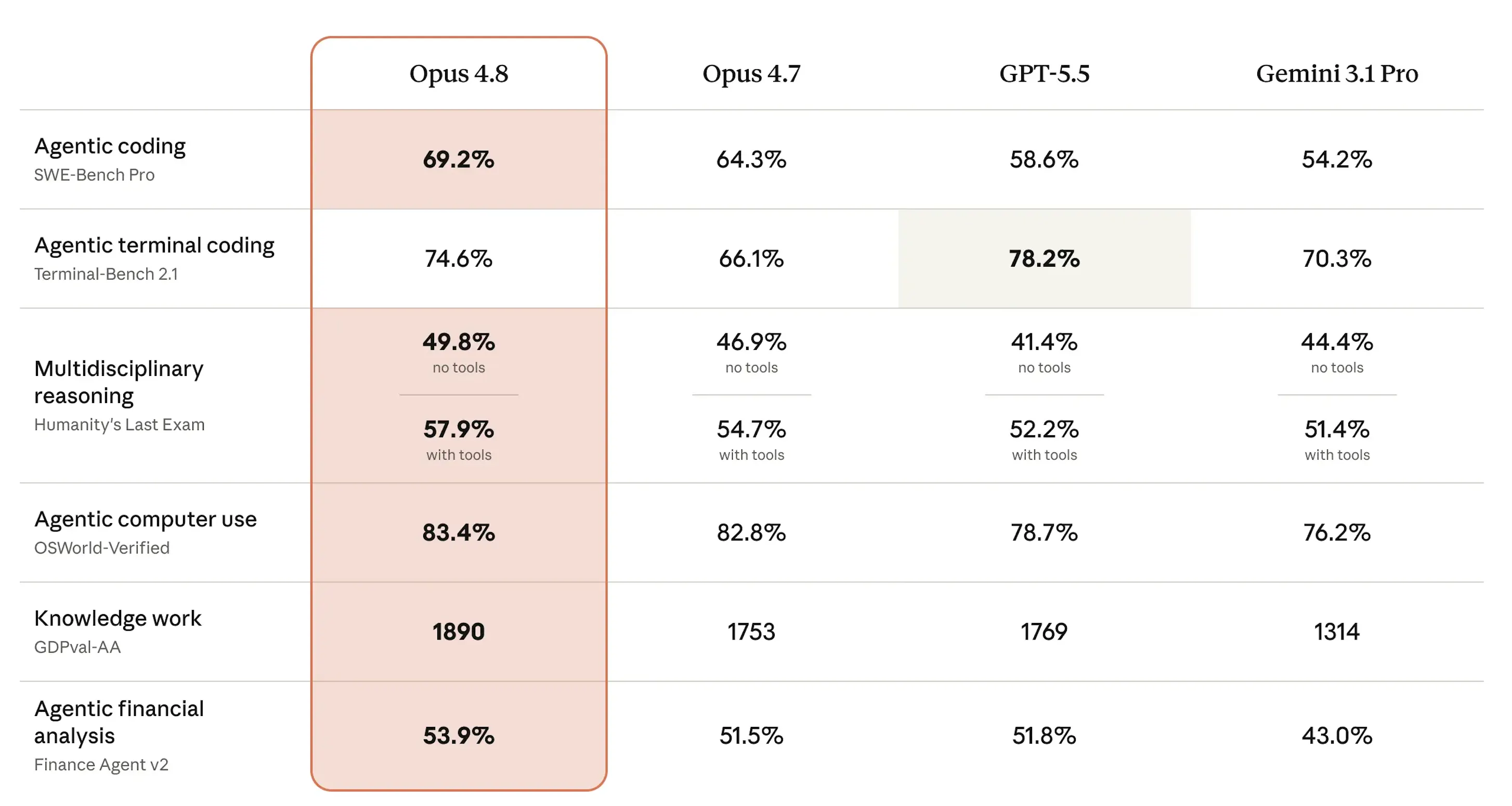
On Humanity’s Final Examination—expert-level questions throughout dozens of educational disciplines, scored as a proportion appropriate—Opus 4.8 reached 49.8% with out instruments and 57.9% with them, forward of all three rivals. OSWorld-Verified, which assessments real-world laptop use duties like navigating software program UIs, got here in at 83.4%, nudging previous Opus 4.7’s rating of 82.8%.
The one loss: Terminal-Bench 2.1, which measures AI efficiency on command-line duties. GPT-5.5 leads at 78.2%, whereas Opus 4.8 scores 74.6%—higher than Opus 4.7’s 66.1% and forward of Gemini’s 70.3%, however second place continues to be finally dropping.
5 methods to assume
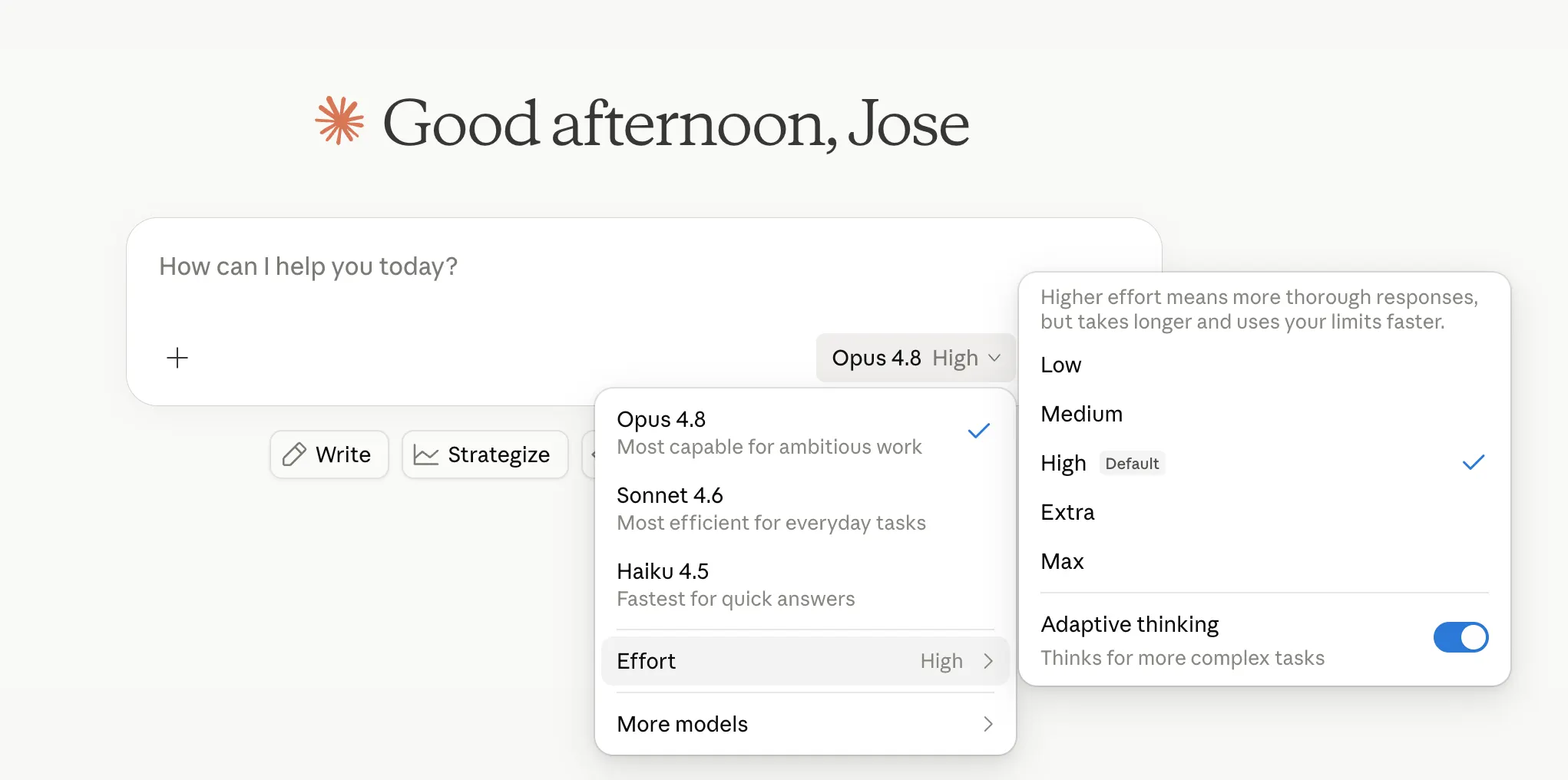
Anthropic is now letting customers management how onerous the mannequin thinks. “Excessive” is the default and handles most duties properly, whereas “Additional”—referred to as “xhigh” inside Claude Code—spends extra compute for more durable issues. “Max” is the deep finish. “Low” and “Medium” dedicate much less tokens to the identical activity, saving a while in alternate for accuracy.
The trouble management sits alongside the mannequin selector in claude.ai and Cowork, accessible on all plans. Anthropic says default excessive makes use of roughly the identical tokens as Opus 4.7’s default with higher outcomes—which is both spectacular engineering or good messaging, and doubtless each.
It’s additionally vital to do not forget that Anthropic’s new tokenizer for Opus makes use of extra tokens per activity. So Claude customers are inevitably sure to burn much more cash to get issues executed, ought to they select Opus as an alternative of Claude Sonnet—a much less succesful mannequin, however most likely ok for on a regular basis duties and sophisticated issues that don’t attain the extent of frontier science or coding.
Price limits in Claude Code had been additionally raised to soak up the upper token spend that the Additional and Max settings produce.
Virtually as protected as Claude Mythos
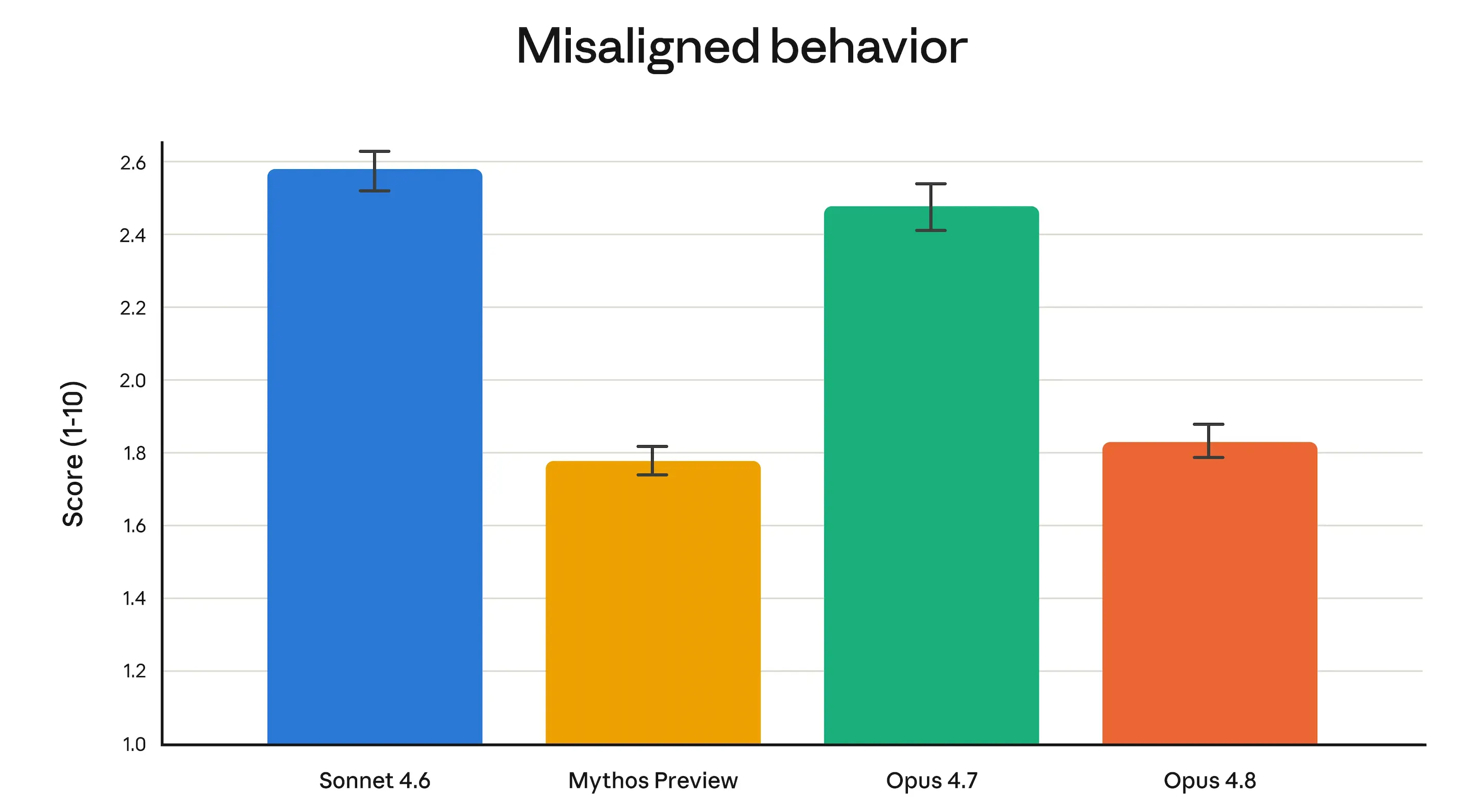
Anthropic’s alignment workforce stated Opus 4.8 “reaches new highs on our measures of prosocial traits like supporting consumer autonomy and appearing within the consumer’s finest curiosity.” Extra concretely: deception charges and misuse-cooperation charges got here in considerably decrease than Opus 4.7, and similar to Claude Mythos Preview—Anthropic’s most locked-down mannequin.
Opus 4.8 can also be 4 instances much less seemingly than 4.7 to let bugs in its personal code slide previous with out flagging them.
That Mythos comparability deserves context. Mythos is a tier above Opus totally—Anthropic describes it as “bigger and extra clever than our Opus fashions.” It at present exists solely as a preview, accessible to a handful of vetted organizations doing cybersecurity work by way of Challenge Glasswing.
The U.Ok.’s AI Safety Institute discovered it might autonomously full “The Final Ones,” a 32-step company community assault simulation that normally takes human purple groups 20 hours. That is why it isn’t but on the market. Anthropic says stronger cyber safeguards are in progress, and expects to carry Mythos-class fashions to everybody “within the coming weeks.”
Additionally delivery as we speak: dynamic workflows in Claude Code, in analysis preview. The function lets Claude write its personal orchestration scripts and spin up parallel subagents in a single session, confirm their outputs, and report again—similar to what Hermes has been doing for some time now.
Dynamic workflows can be found for Enterprise, Crew, and Max plan customers, and Anthropic is upfront that they burn considerably extra tokens than a typical Claude Code session.
The widening worth hole
Anthropic’s $5/$25 pricing appears very completely different subsequent to what China has been doing recently.
DeepSeek V4 Professional made its 75% low cost everlasting final week: $0.435 per million enter tokens and $0.87 per million output tokens. Xiaomi MiMo V2.5 Professional runs on the identical charges by way of suppliers like OpenRouter.
Anthropic’s quick mode prices $10 enter and $50 output per million—costlier than customary Opus 4.8 itself, and roughly 57 instances extra per output token than DeepSeek V4 Professional. Firms have already spent tens of millions of {dollars} in inference on American fashions. Go wild with Opus and your enterprise might attain tens of millions of {dollars} fairly shortly.
Anthropic’s reply to the worth hole is high quality and security. On SWE-bench Professional, Opus 4.8 beats each Chinese language fashions. On alignment, neither comes near Anthropic’s printed benchmarks.
These issues matter in manufacturing environments the place a mannequin quietly cooperating with dangerous inputs is an precise threat—regulated industries, authorized work, and something the place “it appeared advantageous” is not a suitable post-incident report. For everybody else, the hole is difficult to disregard.
We examined it
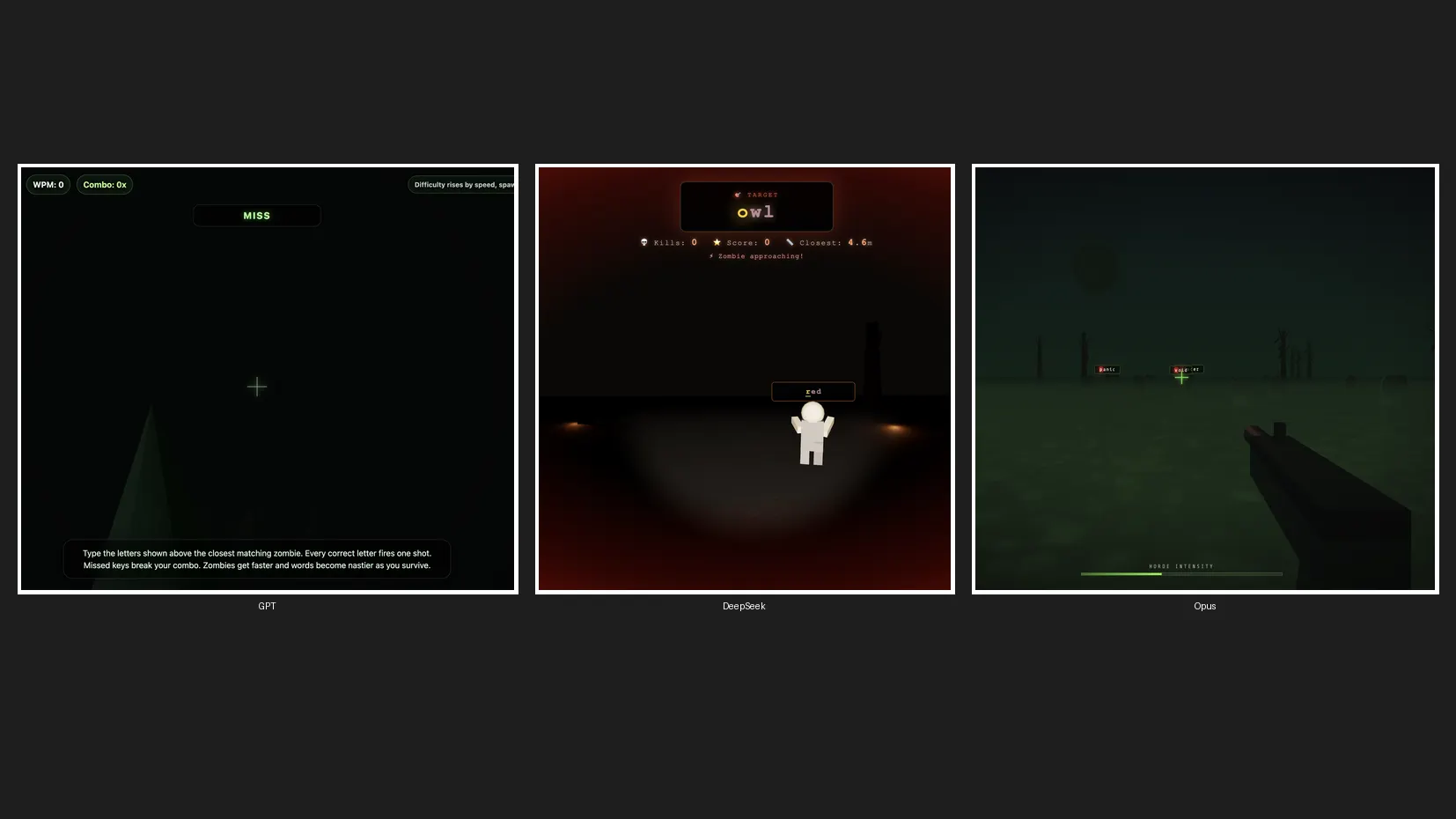
We ran a fast coding check to create a 3D zombie recreation to see how Claude Opus 4.8 stacks in opposition to ChatGPT and DeepSeek, arguably its hottest rivals from the U.S. and China. We set Opus 4.8 on default excessive, GPT-5.5 on excessive effort, and DeepSeek V4 Professional on excessive effort—three fashions, one immediate, no retries.
GPT-5.5 completed first. Its recreation had no zombie visuals and no sound results. It was quick, positive, however it missed the transient totally.
DeepSeek V4 Professional got here in second with mouse motion, precise zombie characters, sound results, strong mechanics, and a clear aesthetic. No complaints there.
Opus 4.8 took roughly thrice so long as GPT-5.5, however delivered the very best splash display, the very best zombie designs, the very best recreation mechanics, and first rate sound results. It was the slowest, however the very best output. Nonetheless, that’s most likely not sufficient to justify utilizing it over DeepSeek, given the price hole.
All of the video games can be found on our Itch.io Profile. GPT-5.5 generated Zombie Typing, Opus generated Typing Lifeless, and DeepSeek v4 Professional generated a recreation with out a identify that takes you proper into the motion. Let’s name it TypeSeek.
A full comparative evaluate is coming. For now: Claude Opus 4.8 codes higher than GPT-5.5 and Opus 4.7 for this sort of activity, on the identical worth Anthropic has charged since 4.7. Builders who had been already paying $5 per million tokens simply obtained a greater mannequin free of charge.
Every day Debrief Publication
Begin day by day with the highest information tales proper now, plus authentic options, a podcast, movies and extra.