
AI corporations used to measure themselves in opposition to business chief OpenAI. No extra. Now that China’s DeepSeek has emerged because the frontrunner, it’s change into the one to beat.
On Monday, DeepSeek turned the AI business on its head, inflicting billions of {dollars} in losses on Wall Avenue whereas elevating questions on how environment friendly some U.S. startups—and enterprise capital— truly are.
Now, two new AI powerhouses have entered the ring: The Allen Institute for AI in Seattle and Alibaba in China; each declare their fashions are on a par with or higher than DeepSeek V3.
The Allen Institute for AI, a U.S.-based analysis group identified for the discharge of a extra modest imaginative and prescient mannequin named Molmo, at present unveiled a brand new model of Tülu 3, a free, open-source 405-billion parameter massive language mannequin.
“We’re thrilled to announce the launch of Tülu 3 405B—the primary utility of absolutely open post-training recipes to the biggest open-weight fashions,” the Paul Allen-funded non-profit stated in a weblog put up. “With this launch, we show the scalability and effectiveness of our post-training recipe utilized at 405B parameter scale.”
For many who like evaluating sizes, Meta’s newest LLM, Llama-3.3, has 70 billion parameters, and its largest mannequin so far is Llama-3.1 405b—the identical dimension as Tülu 3.
The mannequin was so massive that it demanded extraordinary computational sources, requiring 32 nodes with 256 GPUs working in parallel for coaching.
The Allen Institute hit a number of roadblocks whereas constructing its mannequin. The sheer dimension of Tülu 3 meant the workforce needed to break up the workload throughout a whole lot of specialised laptop chips, with 240 chips dealing with the coaching course of whereas 16 others managed real-time operations.
Even with this huge computing energy, the system regularly crashed and required round the clock supervision to maintain it working.
Tülu 3’s breakthrough centered on its novel Reinforcement Studying with Verifiable Rewards (RLVR) framework, which confirmed specific energy in mathematical reasoning duties.
Every RLVR iteration took roughly 35 minutes, with inference requiring 550 seconds, weight switch 25 seconds, and coaching 1,500 seconds, with the AI getting higher at problem-solving with every spherical.
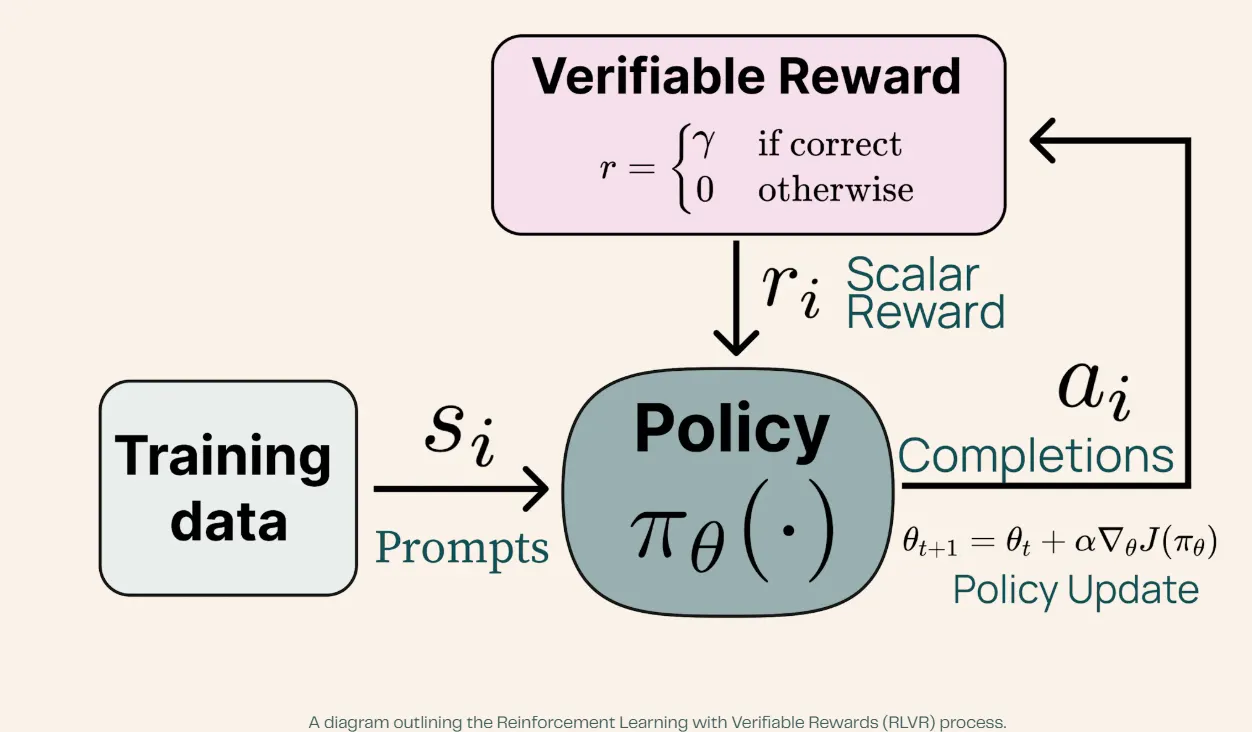
Reinforcement Studying with Verifiable Rewards (RLVR) is a coaching method that looks as if a complicated tutoring system.
The AI obtained particular duties, like fixing math issues, and acquired prompt suggestions on whether or not its solutions have been right.
Nonetheless, not like conventional AI coaching (just like the one utilized by openAI to coach ChatGPT), the place human suggestions could be subjective, RLVR solely rewarded the AI when it produced verifiably right solutions, much like how a math instructor is aware of precisely when a pupil’s resolution is true or incorrect.
This is the reason the mannequin is so good at math and logic issues however not one of the best at different duties like inventive writing, roleplay, or factual evaluation.
The mannequin is on the market at Allen AI’s playground, a free website with a UI much like ChatGPT and different AI chatbots.
Our assessments confirmed what could possibly be anticipated from a mannequin this massive.
It is rather good at fixing issues and making use of logic. We supplied totally different random issues from plenty of math and science benchmarks and it was capable of output good solutions, even simpler to grasp when in comparison with the pattern solutions that benchmarks supplied.
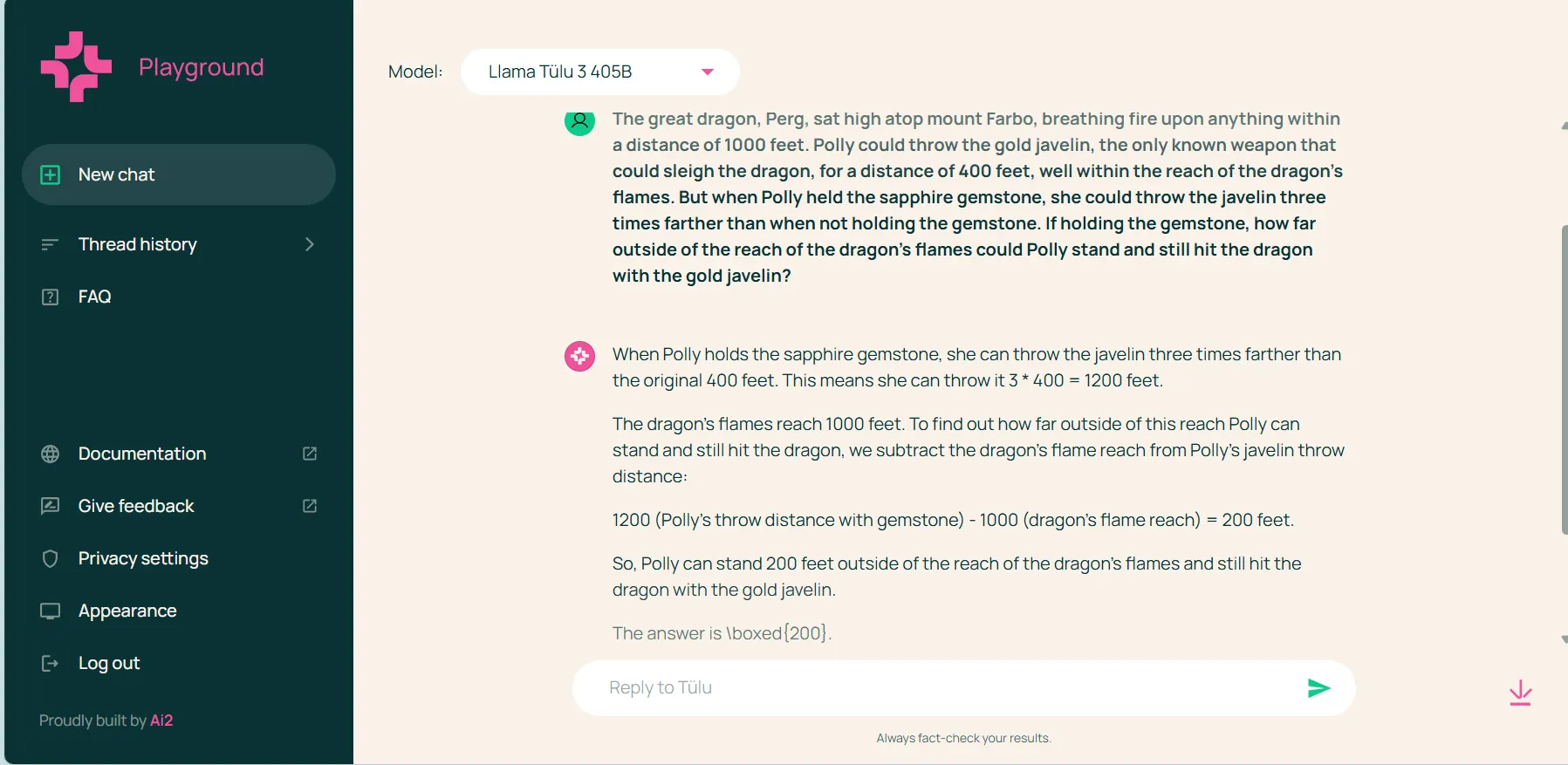
Nonetheless, it failed in different logical language-related duties that didn’t contain math, equivalent to writing sentences that finish in a selected phrase.

Additionally, Tülu 3 isn’t multimodal. As an alternative, it caught to what it knew finest—churning out textual content. No fancy picture era or embedded Chain-of-Thought methods right here.
On the upside, the interface is free to make use of, requiring a easy login, both by way of Allen AI’s playground or by downloading the weights to run regionally.
The mannequin is on the market for obtain by way of Hugging Face, with alternate options going from 8 billion parameters to the big 405 billion parameters model.
Chinese language Tech Large Enters the Fray
In the meantime, China isn’t resting on DeepSeek’s laurels.
Amid all of the hubbub, Alibaba dropped Qwen 2.5-Max, an enormous language mannequin educated on over 20 trillion tokens.
The Chinese language tech big launched the mannequin through the Lunar New 12 months, simply days after DeepSeek R1 disrupted the market.
Benchmark assessments confirmed Qwen 2.5-Max outperformed DeepSeek V3 in a number of key areas, together with coding, math, reasoning, and normal data, as evaluated utilizing benchmarks like Enviornment-Arduous, LiveBench, LiveCodeBench, and GPQA-Diamond.
The mannequin demonstrated aggressive outcomes in opposition to business leaders like GPT-4o and Claude 3.5-Sonne,t in keeping with the mannequin’s card.

Alibaba made the mannequin out there by means of its cloud platform with an OpenAI-compatible API, permitting builders to combine it utilizing acquainted instruments and strategies.
The corporate’s documentation confirmed detailed examples of implementation, suggesting a push for widespread adoption.
However Alibaba’s Qwen Chat net portal is the most suitable choice for normal customers and appears fairly spectacular—for many who are okay with creating an account there. It’s in all probability essentially the most versatile AI chatbot interface at present out there.
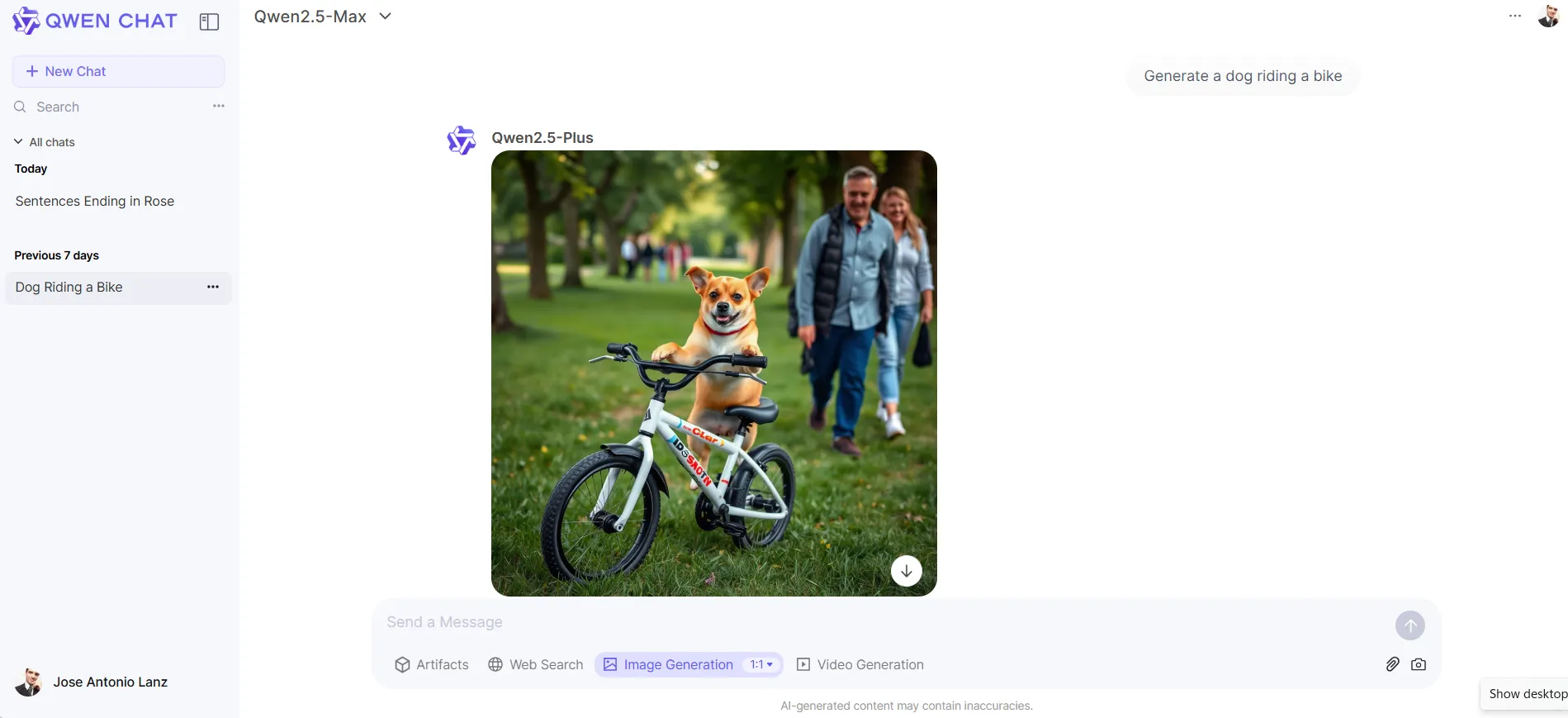
Qwen Chat permits customers to generate textual content, code, and pictures flawlessly. It additionally helps net search performance, artifacts, and even an excellent video generator, all in the identical UI—free of charge.
It additionally has a singular operate through which customers can select two totally different fashions to “battle” in opposition to one another to offer one of the best response.
General, Qwen’s UI is extra versatile than Allen AI’s.
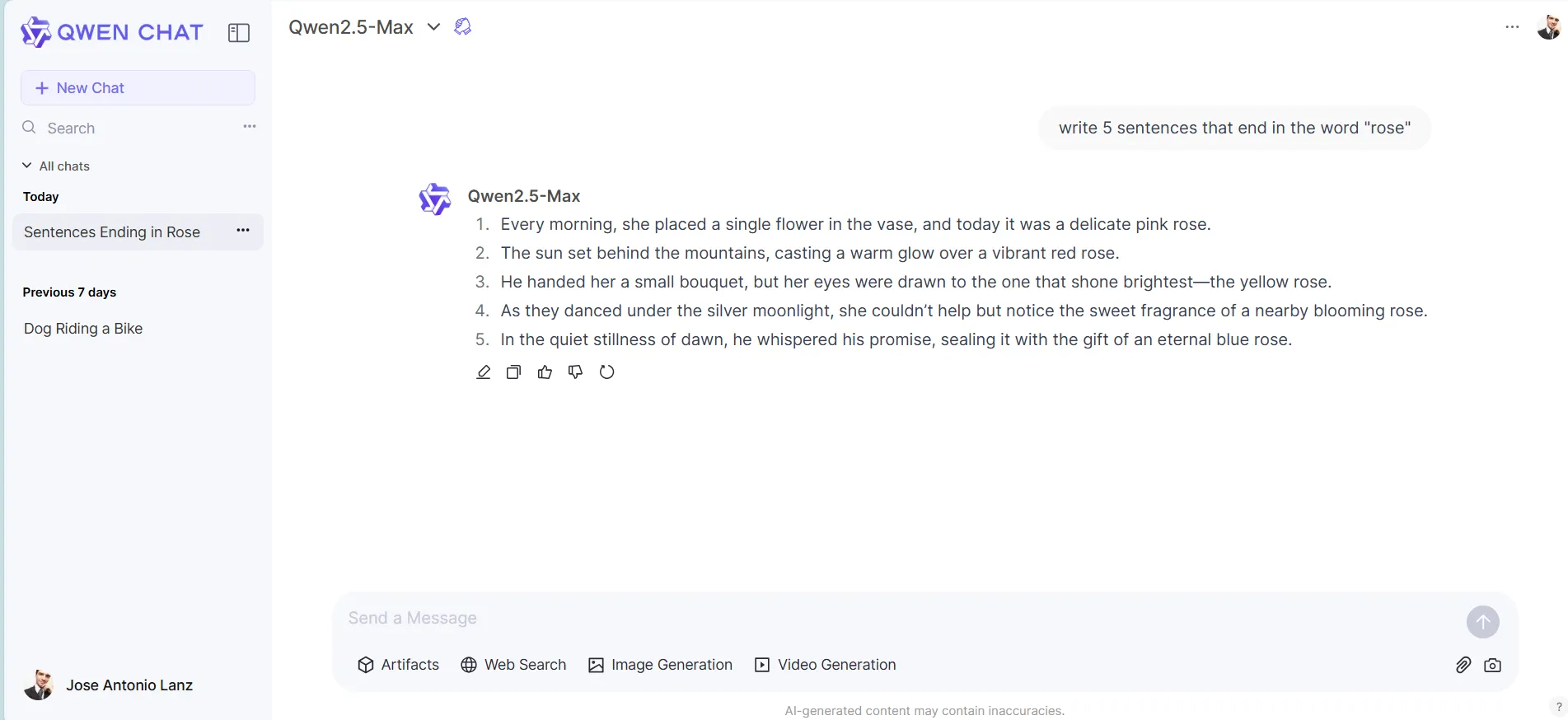
In textual content responses, Qwen2.5-Max proved to be higher than Tülu 3 at inventive writing and reasoning duties that concerned language evaluation. For instance, it was able to producing phrases ending in a selected phrase.
Its video generator is a pleasant addition and is arguably on par with provides like Kling or Luma Labs—positively higher than what Sora could make.
Additionally, its picture generator offers life like and nice photographs, exhibiting a transparent benefit over OpenAI’s DALL-E 3, however clearly behind prime fashions like Flux or MidJourney.
The triple launch of DeepSeek, Qwen2.5-Max, and Tülu 3 simply gave the open-source AI world its most important increase shortly.
DeepSeek had already turned heads by constructing its R1 reasoning mannequin utilizing earlier Qwen know-how for distillation, proving open-source AI may match billion-dollar tech giants at a fraction of the associated fee.
And now Qwen2.5-Max has upped the ante. If DeepSeek follows its established playbook—leveraging Qwen’s structure—its subsequent reasoning mannequin may pack a fair greater punch.
Nonetheless, this could possibly be a great alternative for the Allen Institute. OpenAI is racing to launch its o3 reasoning mannequin, which some business analysts estimated may value customers as much as $1,000 per question.
If that’s the case, Tülu 3’s arrival could possibly be an incredible open-source different—particularly for builders cautious of constructing on Chinese language know-how attributable to safety issues or regulatory necessities.
Edited by Josh Quittner and Sebastian Sinclair
Usually Clever E-newsletter
A weekly AI journey narrated by Gen, a generative AI mannequin.