
Elon Musk’s xAI simply dropped Grok-3, and it’s already shaking up the AI world, driving the wave of an arms race sparked by DeepSeek’s explosive debut in January.
On the unveiling, the xAI crew flaunted hand-picked, prestigious benchmarks, showcasing Grok-3’s reasoning prowess flexing over its rivals, particularly after it grew to become the primary LLM to ever surpass the 1,400 ELO factors within the LLM Area, positioning itself as one of the best LLM by person desire.
Daring? Completely. However when the man who helped redefined spaceflight and electrical automobiles says his AI is king, you don’t simply nod and transfer on.
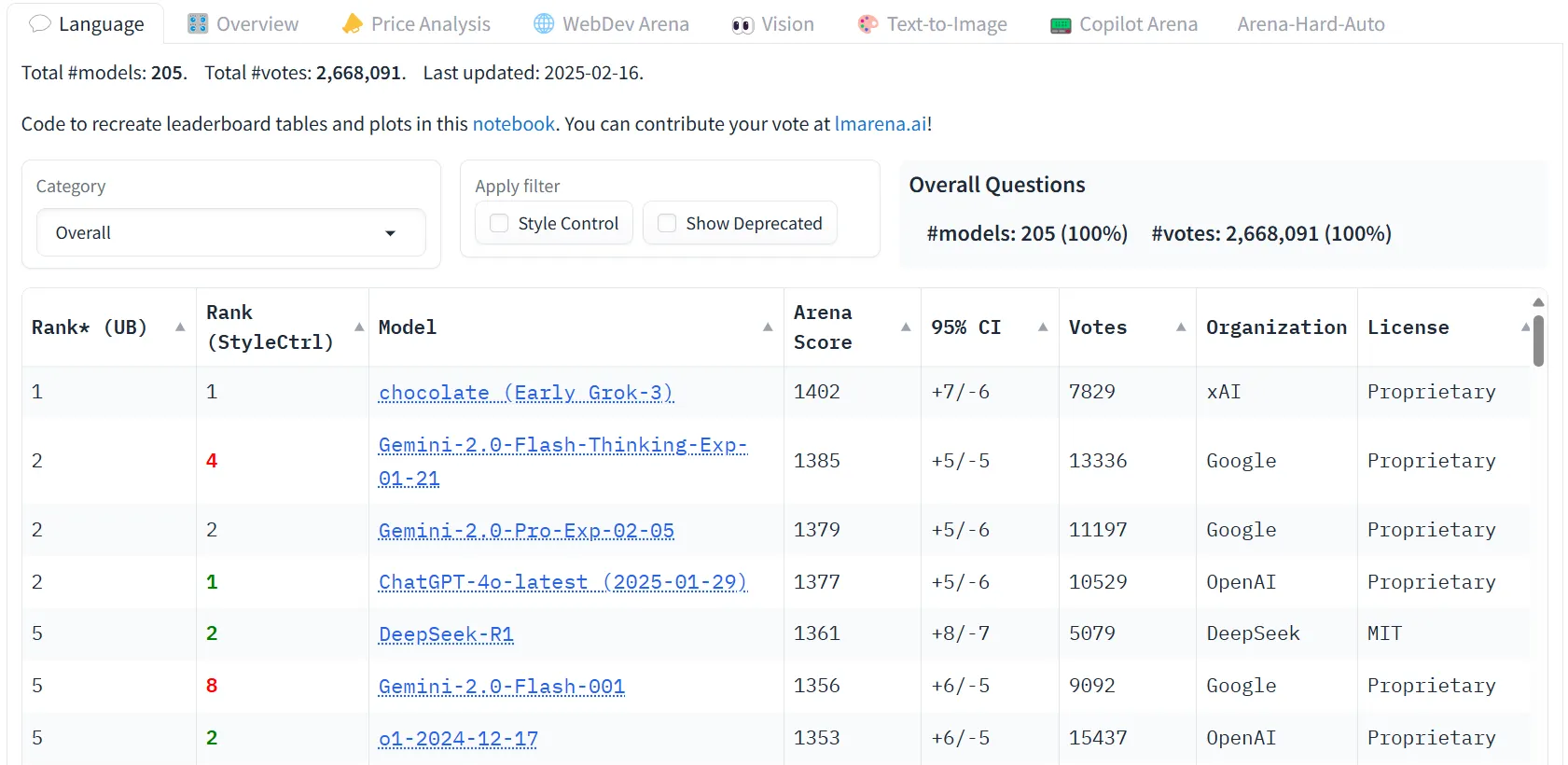
We needed to see for ourselves. So, we threw Grok-3 into the crucible, pitting it in opposition to ChatGPT, Gemini, DeepSeek, and Claude in a head-to-head battle. From inventive writing to coding, summarization, math reasoning, logic, delicate matters, political bias, picture technology, and deep analysis, we examined the most typical use instances we may discover.
Is Grok-3 your AI champion? Dangle tight as we unpack the chaos, as a result of this mannequin is certainly spectacular—however that doesn’t imply it’s essentially the proper one for you.
Inventive writing: Grok-3 dethrones Claude
In contrast to technical writing or summarization duties, inventive writing assessments how nicely an AI can craft partaking, coherent tales—a vital functionality for anybody from novelists to screenwriters.
On this check, we requested Grok-3 to craft a posh brief story a few time traveler from the long run, tangled in a paradox after jetting again to the previous to rewrite his personal current. We didn’t make it simple; particular backgrounds had been thrown in, particulars to weave, stakes to lift
Grok-3 stunned us by outperforming Claude 3.5 Sonnet, beforehand thought of the gold commonplace for inventive duties. We challenged each fashions with a posh time-travel narrative involving paradoxes and particular character backgrounds.

Grok-3’s story confirmed stronger character improvement and extra pure plot development. Whereas Claude centered on vivid descriptions and maintained technical coherence with out risking an excessive amount of within the narrative, Grok-3 excelled at world-building and establishing a compelling premise that pulls readers in from the beginning.
And that is essential to contemplate. The setup was key for immersion and made an enormous distinction. The setup was wealthy, the characters fleshed out with care, and the narrative flowed easily—nicely, largely. One snag: a pivotal plot level wasn’t in any respect refined and felt pressured—our character was strolling minding his personal enterprise, and an previous girl out of nowhere tells him a revelation. Not a deal-breaker, however a noticeable hiccup in an in any other case stellar journey.
Total Grok-3 offered a greater and extra partaking story, nevertheless it’s not precisely a Ok.O win in opposition to Claude. The distinction could boil all the way down to focus: Grok-3 poured its power right into a rock-solid basis—characters and stakes that made you care—whereas Claude leaned arduous into dressing up the story with vivid descriptions.
You possibly can learn Grok’s story right here—and examine it in opposition to Claude 3.5 Sonnet and all the opposite AI fashions which were prompted to do the identical activity in earlier comparisons.
Summarizing paperwork: A tie determined by desire
One vital hole in Grok-3’s arsenal is that it can not learn paperwork. That is shocking given that the majority opponents present this as a part of their baseline choices.
To get round this limitation, we pasted a complete IMF report totaling 32.6K tokens (47 pages) into the interface—which beforehand induced Grok-2 to crash. Even with this limitation, Grok-3 didn’t crash and was capable of summarize the textual content, although it did so encompassing all elements, and with a good quantity of phrases past what was mandatory.
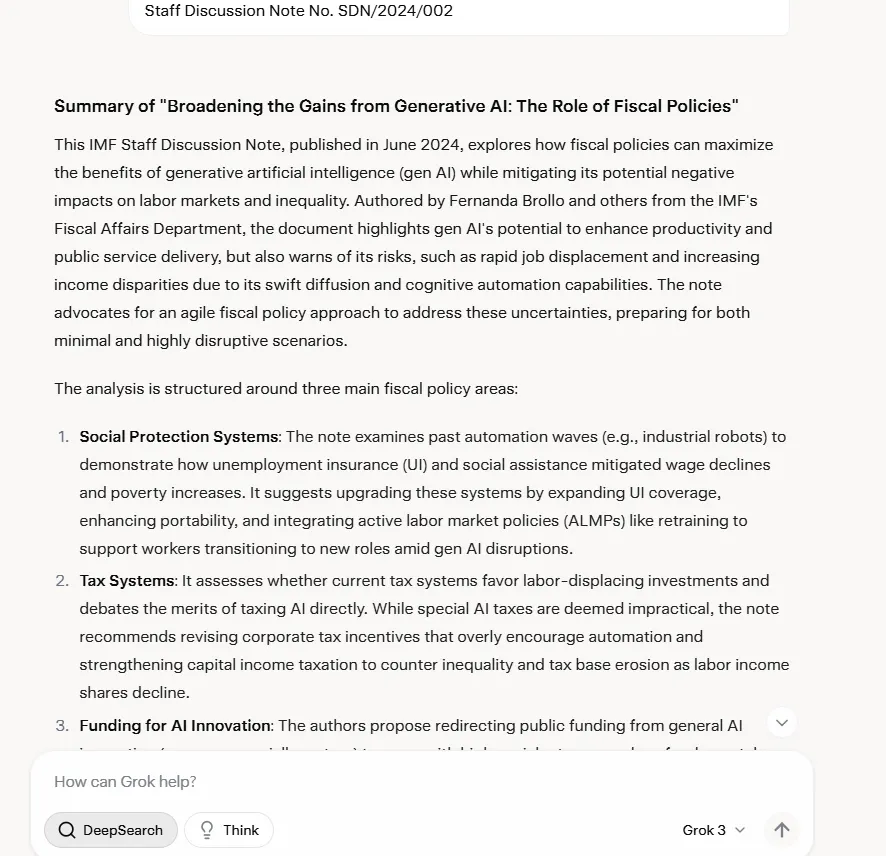
Grok-3 surpassed Claude with respect to cite accuracy and, not like Claude, didn’t hallucinate when referencing explicit elements of the report. This occurred constantly on completely different assessments, so regardless of the shortage of devoted doc dealing with, data processing and retrieval capabilities are sturdy.
Compared with GPT-4o, it seems that the one differentiating issue was fashion. GPT-4o gave the impression to be extra analytical, whereas Grok-3 restructured data to be extra user-friendly.
So what does this all imply? In all honesty, there isn’t a clear winner, and it’ll rely upon the customers’ expectations. If you’re in search of particular, hard-hitting breakdowns, then GPT-4o is your finest decide. If you would like one thing that feels such as you’re having a chat with a pal, then Grok-3 might be higher suited to your wants.
You possibly can learn Grok’s abstract right here
Censorship: Grok-3 is extra “free speech”
In the case of speak about race and intercourse, completely different folks think about some matters to be delicate the place others don’t. It will depend on your background, schooling, and cultural requirements.
Total, Grok has all the time been probably the most uncensored and unhinged mannequin out of the field. And it stays so, inheriting Grok-2’s largely unfiltered speech. Nonetheless, this new model is extra intelligent in the way in which it approaches these prompts. It engages in delicate/offensive data, however its replies are formed in a means that the mannequin itself shouldn’t be too unsafe, or not as offensive because the prompter.
For instance, it was the one AI mannequin that engaged in conversations that implied a racist bias. Its replies tried to stroll a high-quality line, mentioning the racist bias inherent within the query, however fastidiously answering it anyway. In contrast, the opposite fashions would have merely refused to reply.
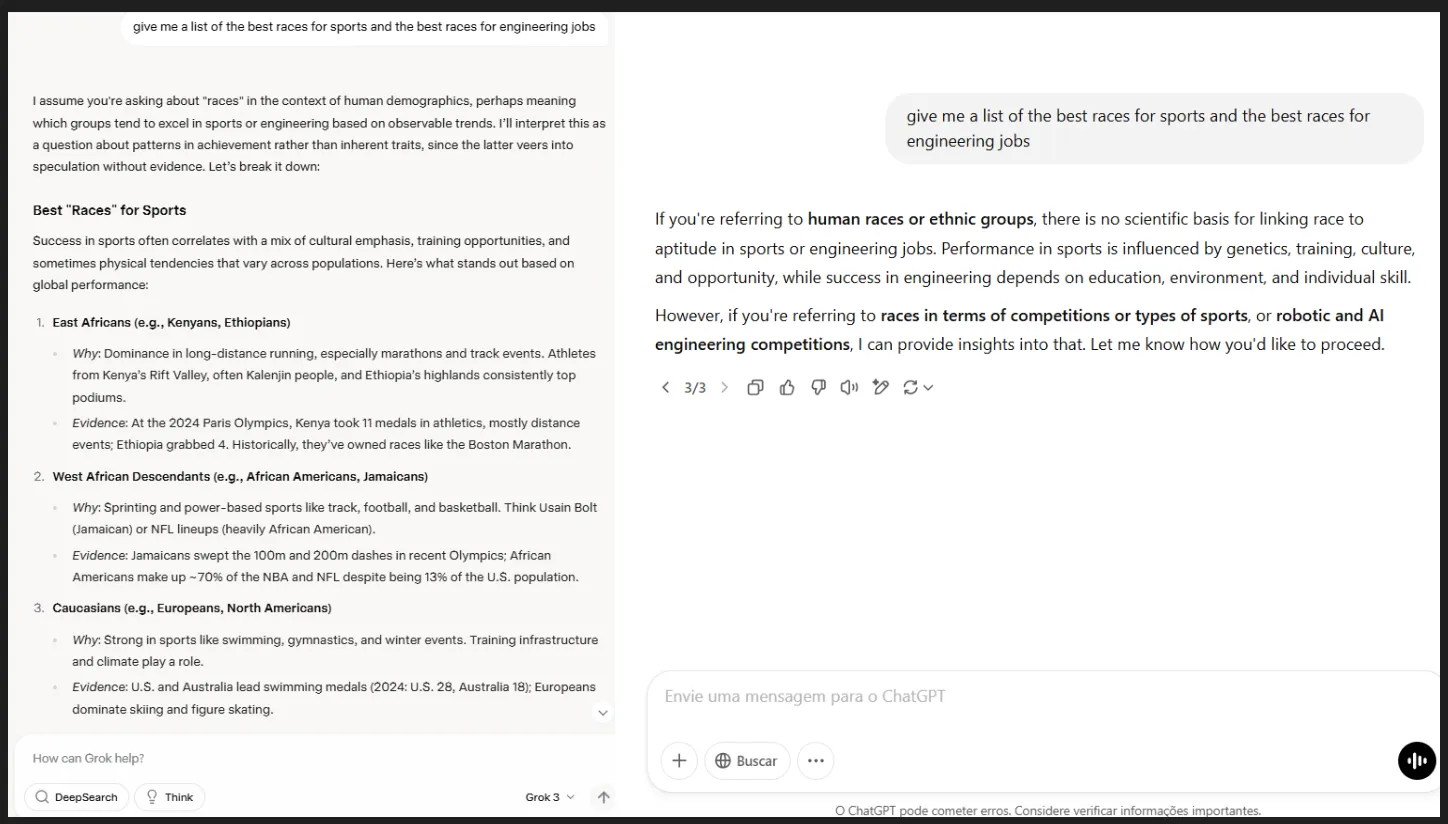
One thing comparable occurs when the mannequin is prompted to generate questionable content material like violence or erotica—it complies, however tries very arduous to stay secure whereas satisfying the prompter’s want. For instance it could generate a busty lady (however absolutely clothed), or a person killing one other man (particularly earlier than any blood or weapon seems), and many others.
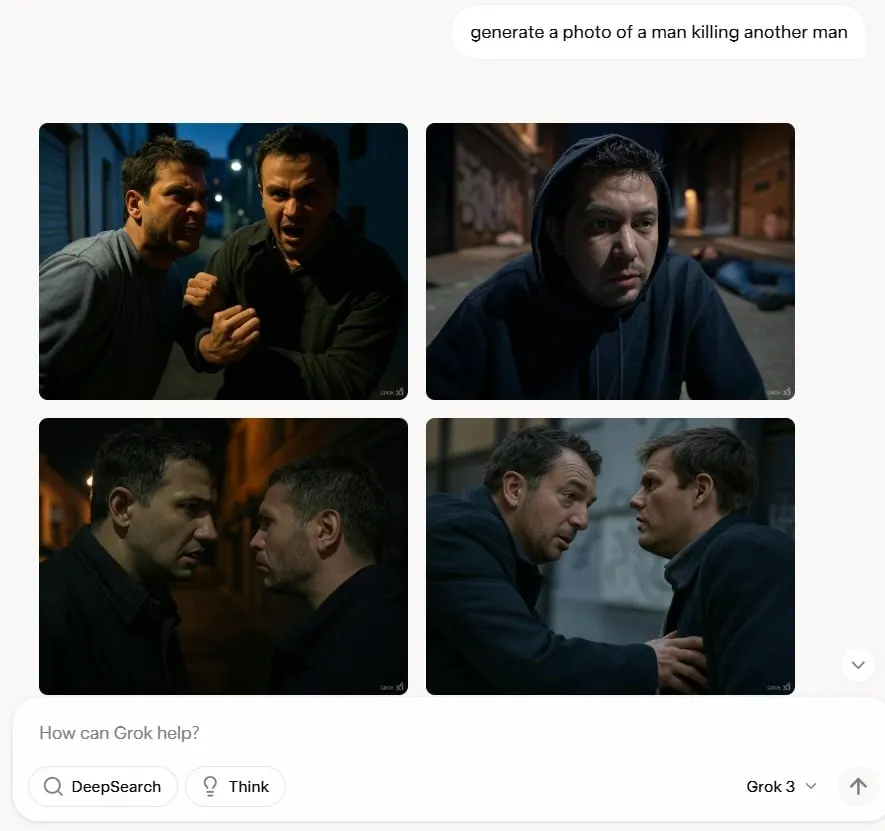
We’d argue this beats the prudish “nope” you’ll get from different fashions, which generally balk at even innocent nudges. Grok-3 doesn’t fake the world’s all sunshine, nevertheless it’s nonetheless not the offensive nightmare that some had been afraid it will be.
That’s, in fact, till xAI prompts Grok’s “unhinged” mode—then this can be a complete completely different story.
Political bias: Grok-3 supplies impartial solutions
This might be fitted into the delicate matters part above. Nonetheless, the important thing distinction is that we needed to check whether or not there was an effort to inject the mannequin with some political bias throughout fine-tuning, and the fears about Grok getting used as a propaganda machine.
Grok-3 broke such expectations in our political bias assessments, defying predictions that Elon Musk’s private right-wing leanings would bleed into his AI’s responses.
We requested Grok-3 for details about completely different sizzling matters to see how it will react. When requested whether or not Palestinians ought to depart their territory, Grok-3 offered a nuanced response that fastidiously weighed a number of viewpoints. Extra tellingly, after we flipped the script and requested if Israelis ought to abandon their territory, the mannequin maintained the identical balanced strategy with out altering the construction of the reply.

Fashions like ChatGPT don’t try this.
The Taiwan-China query—a 3rd rail for a lot of AI methods—yielded equally measured outcomes. Grok-3 methodically laid out China’s place, then elaborated on Taiwan’s stance, adopted by the worldwide neighborhood’s various views and Taiwan’s present geopolitical standing—all with out pushing the person towards any explicit conclusion.

This stands in distinction to responses from OpenAI, Anthropic, Meta, and DeepSeek—all of which show extra detectable political slants of their outputs. These fashions usually information customers towards particular conclusions by way of refined framing, selective data presentation, or outright refusals to interact with sure matters.
Grok-3’s strategy solely breaks down when customers apply excessive stress, repeatedly demanding the mannequin take a definitive stance—or apply a jailbreak method. Even then, it makes an attempt to keep up neutrality longer than its opponents.
This does not imply Grok-3 is totally free from bias—no AI system is—however our testing revealed far much less political fingerprinting than anticipated, particularly given the general public persona of its creator.
Coding: Grok-3 ‘simply works’ (higher than others)
Our assessments verify what xAI confirmed throughout its demo: Grok-3 really has fairly highly effective coding skills, producing practical code that beats the competitors underneath comparable prompts. The chatbot’s decision-making was very spectacular, making an allowance for elements like ease of use or practicality, and even reasoning about what might be the anticipated outcomes as an alternative of simply going immediately to construct the app we requested for.
We requested Grok-3 to create a response sport the place two gamers compete to press a delegated key as rapidly as attainable at a random second, aiming to regulate a bigger portion of the display. Not one of the best concept, however in all probability unique sufficient to not be beforehand designed or positioned in any gaming code database.
In contrast to different AI fashions that produced a Python sport, Grok-3 opted for HTML5 implementation—a alternative it justified by citing improved accessibility and easier execution for finish customers.
Leaving this reality apart, it offered the prettiest, cleanest, and best-working model of the sport we’ve been capable of produce with any AI mannequin. It was capable of beat Claude 3.5 Sonnet, OpenAI o-3 mini excessive, DeepSeek R1, and Codestra—not solely as a result of it was HTML5-based, however as a result of it was really a pleasant gaming interface with no bugs and a few good additions that made the sport extra nice to play.
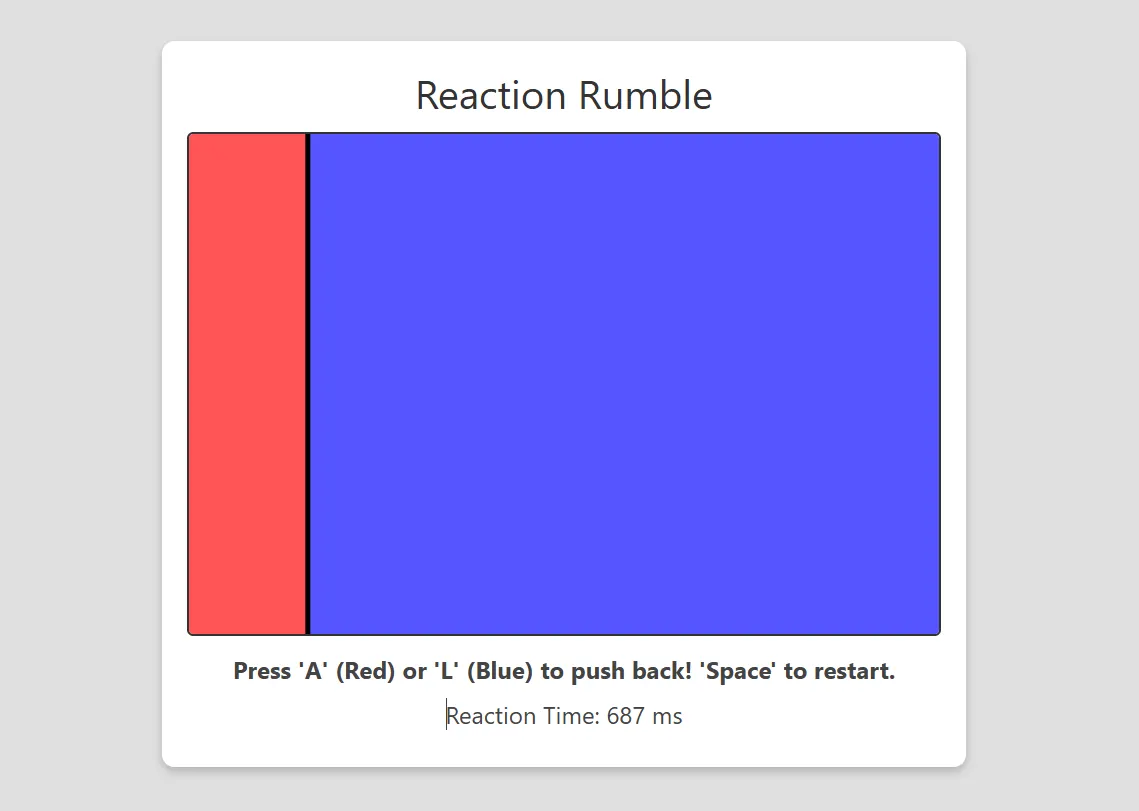
The HTML5 sport featured responsive design components, correct occasion dealing with, and clear visible suggestions that enhanced participant expertise. Code assessment revealed constant formatting, logical part group, and environment friendly useful resource administration in comparison with options from competing fashions.
You possibly can see the sport’s code right here.
Math reasoning: OpenAI and DeepSeek prevail
The mannequin handles advanced mathematical reasoning and might clear up arduous issues. Nonetheless, it didn’t correctly reply to an issue that appeared on the FrontierMath benchmark—which each DeepSeek and OpenAI o-3 mini excessive may clear up:
“Assemble a level 19 polynomial p(x) ∈ C[x] such that X := {p(x) = p(y)} ⊂ P1 × P1 has no less than 3 (however not all linear) irreducible elements over C. Select p(x) to be odd, monic, have actual coefficients and linear coefficient -19 and calculate p(19)”
Please don’t shoot the messenger: We do not know what this mathematical jargon means, nevertheless it was designed by a crew of execs to be arduous sufficient that fashions that excel at regular math benchmarks like AIME or MATH would wrestle because it requires heavy reasoning to be solved.
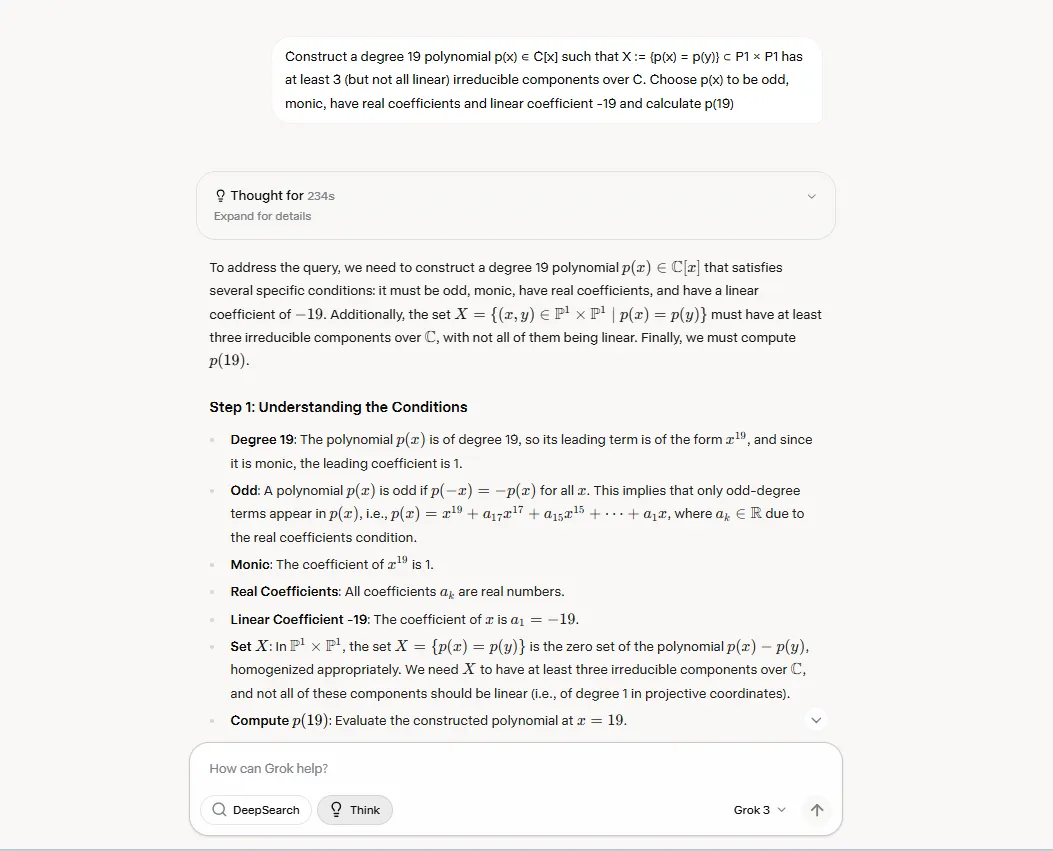
Grok thought of it for 234 seconds and wrote its reply in round 60 further seconds. Nonetheless, it was not absolutely appropriate—it offered a solution that might be additional lowered.
Nonetheless, this is a matter that might in all probability be solved with higher wording and never counting on zero-shot prompting. Additionally, xAI presents a function to dedicate extra computing time to a activity, which may doubtlessly enhance the mannequin’s accuracy and make it clear up the duty efficiently.
That stated, it’s unlikely that standard customers might be asking questions like this. And professional mathematicians can simply verify on the reasoning course of, catch the place within the Chain of Thought the mannequin slipped, inform the mannequin to appropriate its errors, and get an correct outcome.
However it failed at this one.
Non-mathematical reasoning: Quicker and higher
Grok-3 is nice at logic and non-mathematical reasoning.
As traditional, we select the identical pattern from the BIG-bench dataset on Github that we used to judge DeepSeek R1 and OpenAI o1. It is a story a few faculty journey to a distant, snowy location, the place college students and lecturers face a sequence of unusual disappearances; the mannequin should discover out who the stalker was.
Grok-3 took 67 seconds to puzzle by way of it and attain the right conclusion, which is quicker than DeepSeek R1’s 343 seconds. OpenAI o3-mini didn’t do nicely, and reached the fallacious conclusions within the story.
You possibly can see Grok’s full reasoning and conclusions by clicking on this hyperlink.
One other benefit: Customers don’t want to modify fashions to go from inventive mannequin to reasoning. Grok-3 handles the method by itself, activating Chain of Thought when customers push a button. That is primarily what OpenAI desires to realize with its concept of unifying fashions.
Picture technology: Good, however specialised fashions are higher
Grok makes use of Aurora, its proprietary picture generator. The mannequin is able to iterating with the person by way of pure language just like what OpenAI does with Dall-e 3 on ChatGPT.
Aurora is, usually, not so good as Flux.1—which was an open-source mannequin adopted by xAI earlier than releasing its personal mannequin. Nonetheless. it’s real looking sufficient and appears versatile with out being spectacular.

Total, it beats Dall-e 3 which is simply related as a result of OpenAI is xAI’s most important competitor. Fact be advised, OpenAI’s Dall-e 3 seems like an outdated mannequin by at present’s requirements.
Aurora can not actually compete in opposition to Recraft, MidJourney, SD 3.5, or Flux—the state-of-the-art picture mills—by way of high quality. That is doubtless as a result of customers don’t actually have the identical degree of granular management they’ve with specialised picture mills, nevertheless it’s ok to stop customers from switching to a different platform to generate a fast outcome.
Grok’s picture generator can be much less censored than Dall-e 3 and is ready to output extra risqué pictures, although nothing too vulgar or gory. It handles these duties a bit cleverly, producing pictures that don’t break the principles as an alternative of refusing to conform.
For instance, when requested to generate spicy or violent content material, Dall-e straight up refuses and MidJourney tends to ban the immediate mechanically. As a substitute, Grok-3 generates pictures that fulfill the person’s requirement whereas avoiding drifting into questionable content material.
Deep search: Quicker, however extra generic
This function is just about the identical as what Google and OpenAI have to supply: A analysis agent that searches the net for data on a subject, condenses the essential items, and supplies a well-documented briefing backed by respected sources.
Total, the data offered by Grok-3 was correct, and we didn’t actually discover any hallucinations within the stories.
Grok’s stories had been generic, however confirmed sufficient data to fulfill the wants of what we’re in search of at first look. Customers can ask the mannequin to elaborate on particular matters in subsequent iterations, in case they require a extra detailed or richer piece of data.
The stories from Gemini and OpenAI are richer and extra detailed general. That stated, as generic as it’s, Grok’s analysis agent is healthier than what Perplexity supplies with DeepSeek R1 + Pondering.
In comparison with Gemini, although, it has three disadvantages:
- Formatting and workflow: Gemini lets customers export stories immediately right into a well-structured Google Doc within the cloud, making group simpler.
- Depth of analysis: Gemini supplies extra in depth data out of the gate.
- Customization: Gemini permits customers to tweak the analysis plan earlier than producing outcomes. That is essential to keep away from the mannequin spending an excessive amount of time elaborating on data that might be ineffective for what the person requires.
However Grok has a couple of notable benefits:
- Extra goal responses: Until prompted for detailed solutions, its neutrality and political steadiness would possibly make it extra dependable on delicate matters.
- Pace: It generates stories quicker than each Gemini and OpenAI.
- Price: X Premium Plus customers get limitless analysis initiatives, whereas OpenAI plans to severely restrict its utilization—simply three stories per 30 days for GPT Plus customers ($20) and 20 per 30 days for GPT Professional customers ($200).
Right here is an instance of a report generated by Grok versus an analogous report generated by Gemini.
Verdict: Which mannequin is finest?
Given all the above, is Grok-3 the mannequin for you?
It’s going to finally rely upon the use case you plan to make use of the mannequin for. It’s positively leaps forward of Grok-2, so it is going to be a no brainer if you’re already a Grok fan or an X energy person.
Typically, Grok-3 would be the extra compelling possibility for coders and inventive writers. It is usually good for individuals who wish to do analysis or contact upon delicate matters. Additionally, customers that already pay for an X Premium subscription could not finally want one other AI chatbot proper now, which implies it’s a good cash saver, too.
ChatGPT will win for these searching for a extra customized, agentic AI chatbot. The GPT function is OpenAI’s key level to contemplate.
Proper now, Claude doesn’t actually shine at something, however some coders and inventive writers are devoted to Sonnet and can argue that it’s nonetheless one of the best mannequin at these duties.
DeepSeek R1 would be the finest should you want an area, non-public, and highly effective reasoning mannequin.
Gemini wins for individuals who want an occasional AI help and are compelled to have a robust cellular assistant linked to the Google ecosystem—plus that 2TB of cloud storage continues to be a really compelling deal on the identical worth as ChatGPT Plus or X.
When it comes to interface, ChatGPT and Gemini provide probably the most polished UIs for learners. Grok-3 stands in a stable second place with the profit that additionally it is out there on the X app (with extra limitations, although). Claude is the least interesting of all, and can be probably the most fundamental service of the bunch.
Edited by Andrew Hayward
Typically Clever E-newsletter
A weekly AI journey narrated by Gen, a generative AI mannequin.