
In short
- OpenAI argues that SWE-bench Verified not displays actual coding skill as a result of the benchmark is allegedly contaminated.
- It’s now pushing SWE-bench Professional as more durable alternative.
- Scores plunged from ~70% to ~23% on the newer benchmark,
The quantity that each main AI lab has been utilizing to assert coding supremacy was simply declared meaningless.
OpenAI printed a submit this week saying that SWE-bench Verified, the go-to benchmark for measuring AI coding capabilities, is so riddled with flawed assessments and coaching knowledge leakage that it not tells you something helpful about whether or not a mannequin can truly write software program.
The benchmark works like this: Give an AI an actual GitHub challenge from a preferred open-source Python undertaking, ask it to repair the bug with out seeing the assessments, and test if its patch makes the failing assessments cross with out breaking anything.
OpenAI created SWE-bench Verified in August 2024 as a cleaner model of the unique 2023 benchmark, recruiting 93 software program engineers to filter out duties that have been unimaginable or poorly designed.
The cleanup labored nicely sufficient that each main lab began citing scores on it as proof of progress. When Anthropic launched Claude Opus 4 in Could 2025, Decrypt reported that the mannequin scored 72.5% on SWE-bench Verified, beating GPT-4.1’s 54.6% and Gemini 2.5 Professional’s 63.2%. It was the coding benchmark that mattered.
Since then, each single AI lab from America to China has proven the SWE efficiency to assert the throne as the perfect mannequin for coding capabilities.
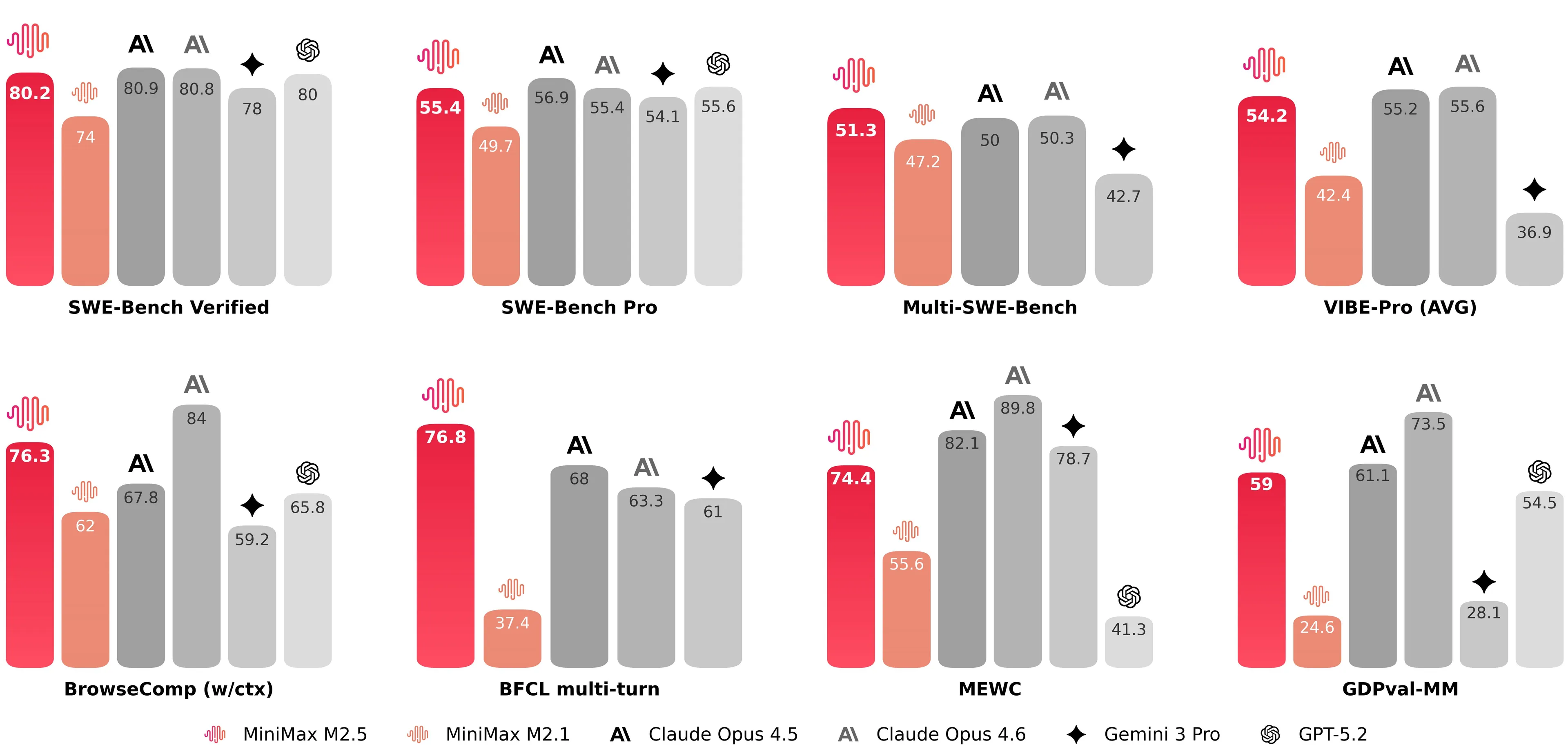
Now OpenAI says that race was partly a mirage. Based on the report, the crew audited 138 duties that GPT-5.2 constantly failed throughout 64 impartial runs, and had six engineers evaluation every one. It in the end concluded that 59.4% of these duties are damaged.
About 35.5% have assessments so narrowly written that they require a selected operate title by no means talked about in the issue description. One other 18.8% test for options that weren’t a part of the unique drawback in any respect, gathered from unrelated pull requests.
The contamination drawback roughly works like this: SWE-bench pulls its issues from open-source repositories that the majority AI firms crawl when constructing coaching units. OpenAI examined whether or not GPT-5.2, Claude Opus 4.5, and Gemini 3 Flash Preview had seen the benchmark’s options throughout coaching. All three had.
Given solely a job ID and a short trace, every mannequin might reproduce the precise code repair from reminiscence, together with variable names and inline feedback that seem nowhere in the issue description. In a single case, GPT-5.2’s chain-of-thought logs confirmed it reasoning {that a} particular parameter will need to have been “added round Django 4.1″—a element discovered solely in Django’s launch notes, not the duty description. It was answering a query it had already seen the reply to.
OpenAI now recommends SWE-bench Professional, a more moderen benchmark from Scale AI that makes use of extra numerous codebases and licenses that cut back coaching knowledge publicity. The efficiency drop is jarring: fashions that cleared 70% on the outdated Verified benchmark rating round 23% on SWE-bench Professional’s public cut up, and even much less on its personal duties.
On the present public SWE-bench Verified leaderboard, OpenAI is much from the benchmark’s podium. Retiring a benchmark the place you are shedding and endorsing one the place everybody begins at 23% resets the scoreboard at a handy second and makes the rivals’ claims much less spectacular.
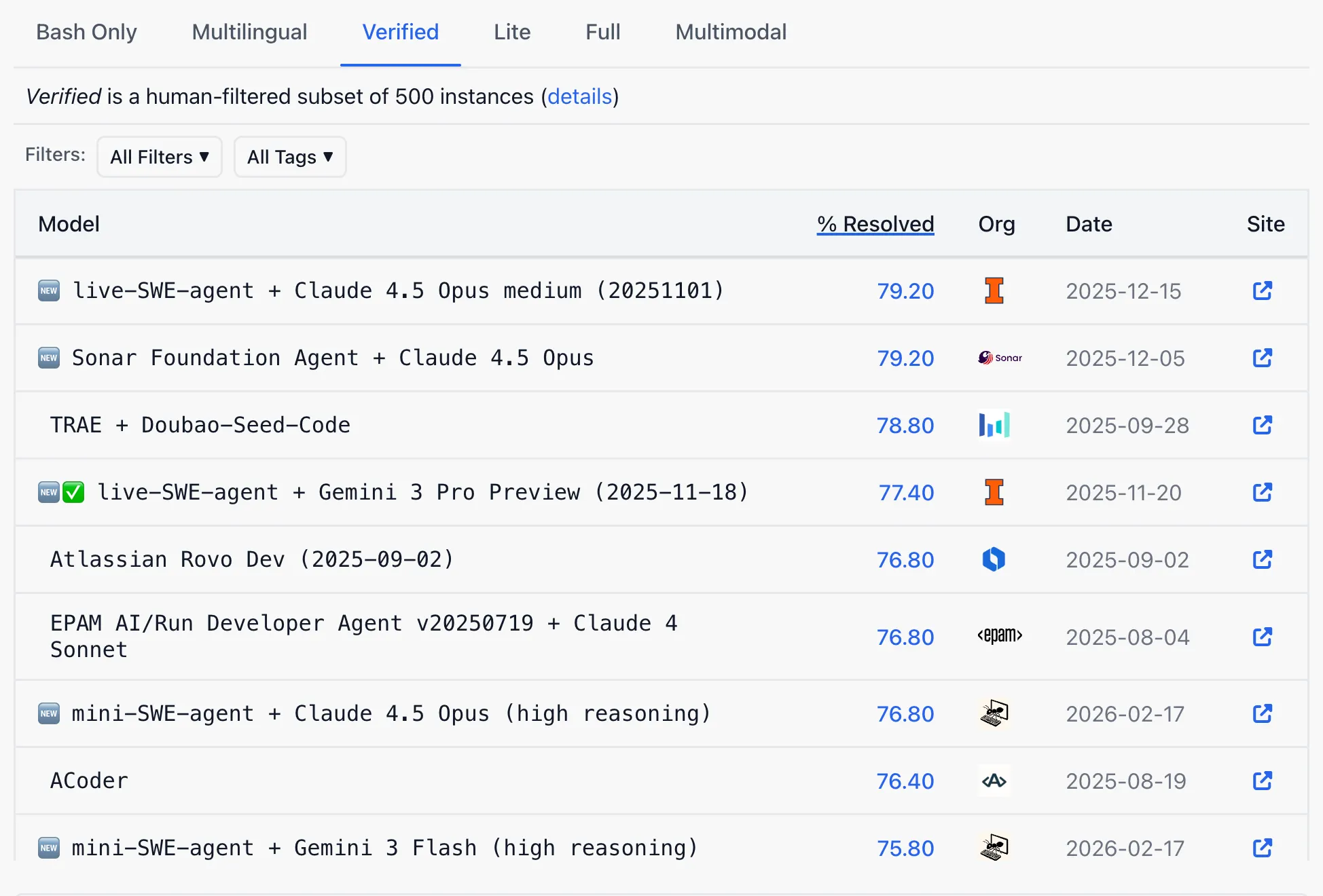
That is particularly essential contemplating that the a lot anticipated newer model of DeepSeek is rumored to beat or get extraordinarily near American ai fashions, particularly in agentic and coding duties with a free, open-source mannequin. That mannequin may very well be days away from launch, and SWE-bench Verified could be a key metric to measure its high quality.
OpenAI mentioned it is constructing privately authored evaluations that will not be launched earlier than testing, pointing to its GDPVal undertaking the place area consultants write authentic duties graded by educated human reviewers.
The benchmark drawback isn’t new, and isn’t distinctive to coding. AI labs have cycled via a number of evaluations, every helpful till fashions have been educated on them or till the duties proved too slim.
However what makes this case notable is that OpenAI hyped SWE-bench Verified, promoted it throughout mannequin releases, and is now publicly documenting how completely it has failed—together with by exhibiting their very own mannequin dishonest on it.
Day by day Debrief Publication
Begin day by day with the highest information tales proper now, plus authentic options, a podcast, movies and extra.