Mistral Medium 3.5 is a 128 billion parameter dense mannequin priced at $1.50 enter / $7.50 output per million tokens, far above comparable Chinese language options.
Chinese language open-source fashions—Qwen, GLM, MiMo-V2—dominate the leaderboard prime, leaving Mistral as a lonely Western holdout.
Mistral is positioning the discharge as a constructing block towards a future massive flagship mannequin.
Mistral AI dropped Mistral Medium 3.5 on April 29. The Paris-based lab introduced a dense 128-billion-parameter mannequin, a set of agentic options—and walked straight right into a wall of on-line “meh” reactions.
The discharge got here in three elements. First, the mannequin itself. Second, distant coding brokers through Mistral Vibe CLI—cloud-based coding periods that may push pull requests to GitHub and run in parallel with out you sitting at a terminal. Third, Work Mode in Le Chat, Mistral’s ChatGPT-style client interface, which now handles multi-step autonomous duties like e-mail triage, analysis synthesis, and cross-tool workflows.
Huge ambitions, however a messy benchmark actuality.
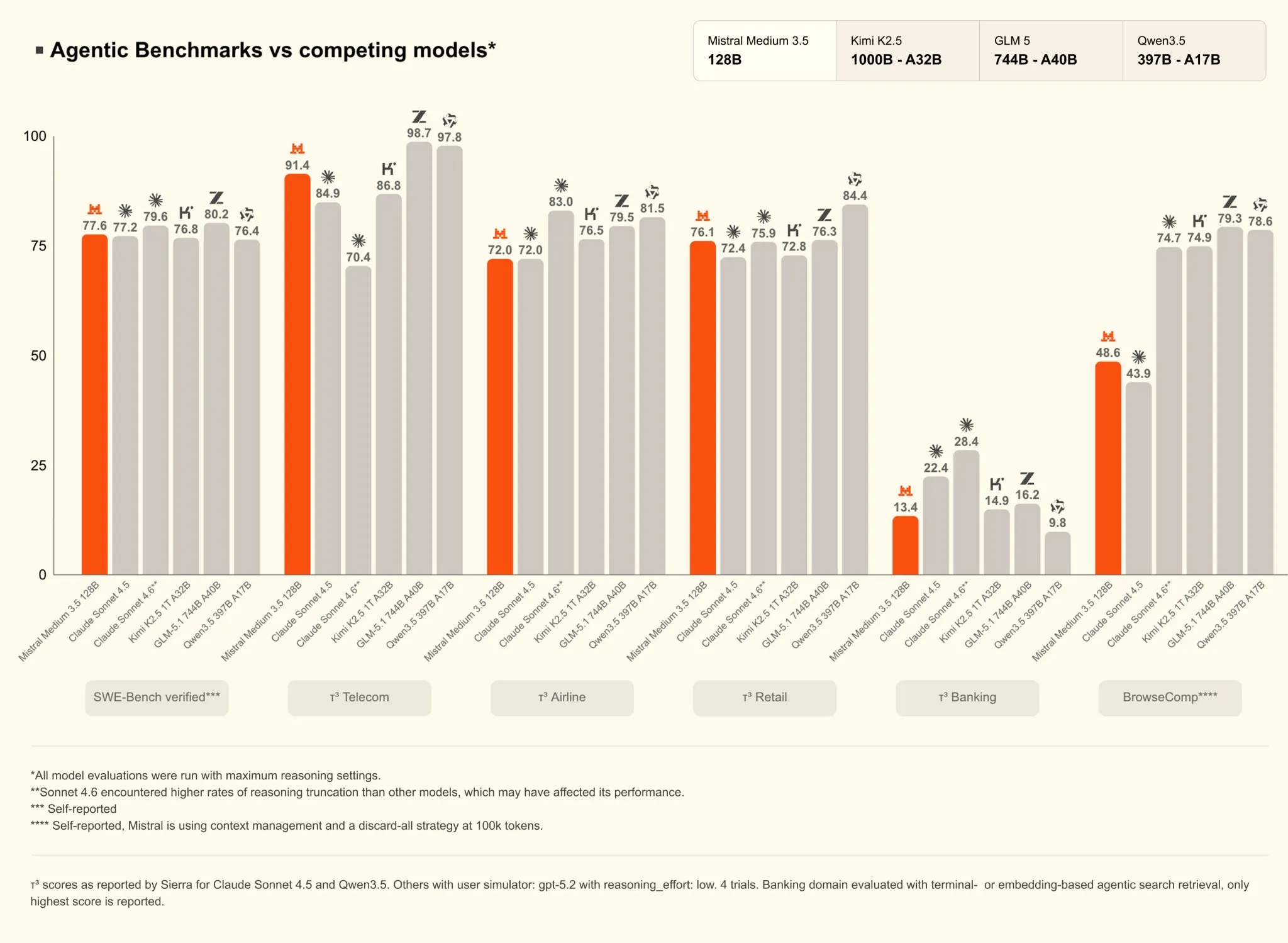
Medium 3.5 scores 77.6% on SWE-Bench Verified—a coding benchmark that assessments whether or not a mannequin can repair actual GitHub points by producing working patches. It additionally hits 91.4% on τ³-Telecom, which measures agentic software use in specialised environments. Mistral additionally merged three beforehand separate fashions (Medium 3.1, Magistral, and Devstral 2) into one set of weights with configurable reasoning effort per request.
Unified mannequin changing three is an actual engineering win. The issue is what it prices and who it is up towards.
Mistral costs $1.50 per million enter tokens and $7.50 per million output tokens. Alibaba’s Qwen 3.6 at 27 billion parameters—lower than 1 / 4 of Medium 3.5’s parameter rely—scores 72.4% on the identical SWE-Bench Verified benchmark and ships beneath Apache 2.0, which means you possibly can obtain and run it totally free.
Do you know?
Parameters are what decide an AI’s capability to study, motive, and retailer info. The extra parameters, the broader the mannequin’s breadth of information.
Scroll by means of the open-source leaderboards and the image is stark. The highest spots belong to Alibaba’s Qwen, GLM from China’s Zhipu AI, and MiMo-V2 from Xiaomi, all of them cheaper, extra highly effective and aggressive than Mistral’s new launch. Medium 3.5 hasn’t even ranked on main impartial leaderboards but—third-party evaluations are nonetheless pending.
The one good factor although, as some argue, is that Mistral is, at this level, the lone non-Chinese language mannequin with any severe presence within the open-source dialog.
I feel Mistral has the tenth highest valuation in the entire AI scene (one thing like that).
All whereas they persistently launch a number of the worst fashions.
They’ve survived by means of European forms, lobbying and politics.
All as a result of they’ve satisfied demented bureaucrat… https://t.co/kh7ASvdi7C
Pedro Domingos, a machine studying professor on the College of Washington, wasn’t mild:
“Common AI corporations brag about how significantly better their mannequin is on benchmarks. Solely Mistral brags about how a lot worse its one is.”
Common AI corporations brag about how significantly better their mannequin is on benchmarks. Solely Mistral brags about how a lot worse its one is. pic.twitter.com/WcAKskaVpL
He adopted up with a sharper query: “I do not know what’s worse, for Europe to not be within the AI race or for it to be represented by a laughingstock like Mistral.”
Youssof Altoukhi, founding father of Yoyo Studios, did the maths: Qwen 3.6, at 27 billion parameters, is 4.7 occasions smaller than Medium 3.5 and scores comparably on coding. Medium 3.5’s output pricing places it alongside closed fashions that rating considerably increased on each main benchmark.
“If it wasn’t for his or her political talent they might have been bankrupt by now,” he mentioned.
Not everybody was purely dismissive. AI developer Michal Langmajer captured the ambivalence:
“I am genuinely glad there’s nonetheless a non-US, non-Chinese language lab making an attempt to construct frontier LLMs however boy we now have to stage up the sport in Europe. Their new flagship mannequin is principally ‘not the most effective’ on any benchmark, but prices a number of occasions greater than most rivals.”
I’m genuinely glad there’s nonetheless a non-US, non-Chinese language lab making an attempt to construct frontier LLMs (@MistralAI) however boy we now have to stage up the sport in Europe.
Their new flagship mannequin is principally “not the most effective” on any benchmark, but prices a number of occasions greater than most rivals… pic.twitter.com/JwvR5eKWmT
Some builders argued open weights are a sturdiness play, not a leaderboard play. A mannequin anybody can obtain, fine-tune, and self-host would not have to win rankings right now to remain related. Others pointed to Mistral’s actual enterprise deployments throughout Europe as proof the moat is not purely technical.
The Geopolitical security web
That is the place Mistral’s precise pitch lives.
European enterprises beneath GDPR, banks dealing with delicate buyer information, and governments that will not route AI workloads by means of Chinese language infrastructure have restricted choices. As Decrypt reported final December, HSBC signed a multi-year cope with Mistral particularly to self-host fashions by itself infrastructure. The enchantment of an EU-headquartered open-weight lab with a $14 billion valuation would not present up in benchmark tables—but it surely reveals up in procurement choices.
Not the most effective at coding, and never the most affordable. However it’s: not American, not Chinese language, auditable, self-hostable, and legally secure for European enterprise.
Day by day Debrief Publication
Begin day by day with the highest information tales proper now, plus unique options, a podcast, movies and extra.