
In short
- 5 frontier AI fashions disagreed on 67% of 1,000 real-world fact-check claims.
- Unanimous settlement occurred on solely 328 claims.
- At 0.639 Krippendorff’s alpha, the fashions fall under the 0.8 reliability threshold.
Ask 5 of the world’s most superior AI programs whether or not an announcement is true, and two-thirds of the time, no less than one provides you with a special reply. That is the discovering of a brand new examine revealed this month by researcher Kosta Jordanov at Lenz Analysis.
The examine gave GPT-5.4, Claude Opus 4.7, Gemini 3 Professional, Gemini 3 Professional with Search, and Sonar Professional the identical 1,000 real-world fact-check claims submitted by precise customers. The fashions needed to choose considered one of 4 labels: true, largely true, deceptive, or false.
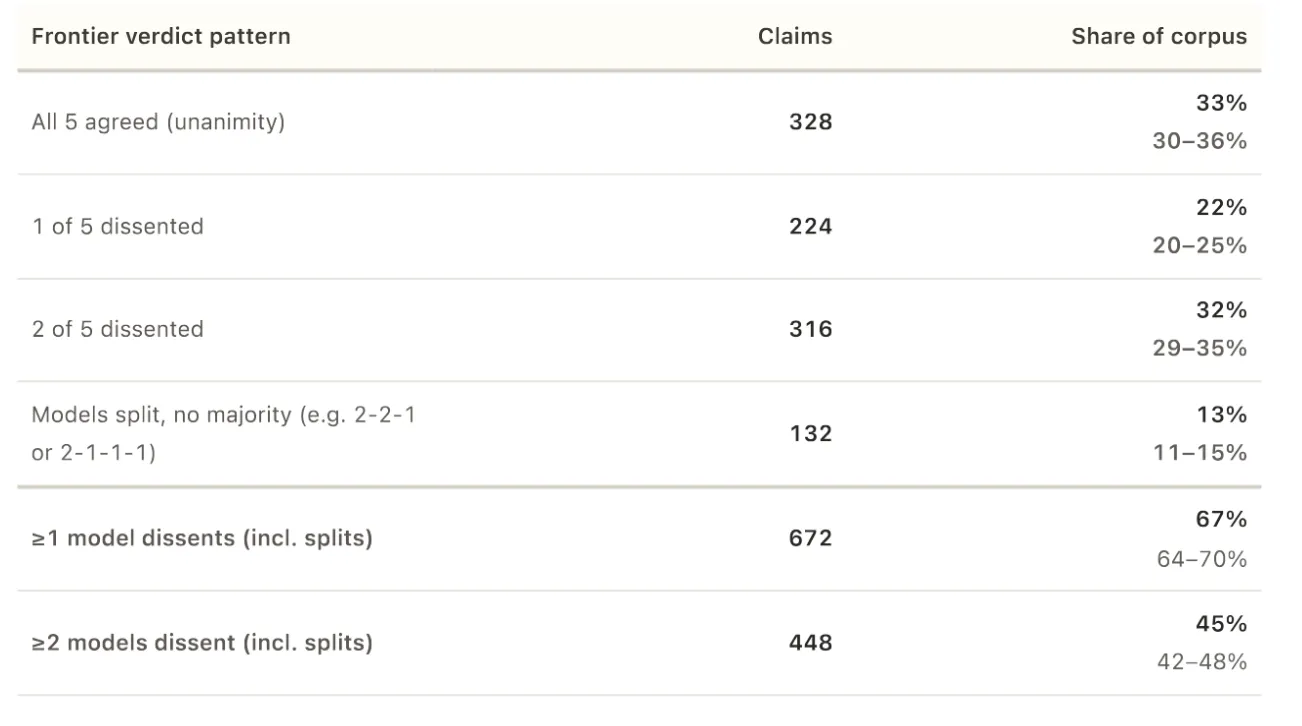
On 672 out of 1,000 claims, no less than one mannequin broke from the bulk. In 34% of circumstances, the disagreement was extreme: one mannequin known as a declare true whereas one other known as it false.
“These aren’t benchmark objects with public reply keys—they’re claims actual customers submitted for verification to a fact-checking platform,” the examine reads. “Just one verdict bucket could be appropriate per declare, so any disagreement among the many panel means no less than one mannequin’s verdict is label-inconsistent beneath this 4-bucket rubric.”
Earlier research on AI hallucination have proven that chatbots invent info. That’s one drawback. It is a totally different one. The fashions aren’t essentially making issues up, they simply can’t agree on fundamental factual judgments about the identical materials.
The analysis used a setup that makes it more durable for the AI firms to clarify away. As an alternative of pulling claims from commonplace check units—the type that usually leak into coaching information—the researchers used claims submitted by actual individuals to Lenz’s fact-checking platform. “Most of those claims are unlikely to seem in any coaching corpus with a gold label hooked up—there’s no canonical reply key to pattern-match in opposition to, no benchmark leaderboard to anchor to,” the paper notes.
The statistical measure of settlement, known as Krippendorff’s alpha, got here in at 0.639 on a scale the place 1.0 means excellent settlement and 0 means random probability. The examine says this means “nontrivial however restricted settlement.” “The fashions’ verdicts are structured slightly than random, however not constant sufficient to deal with the panel as a single interchangeable decide,” researchers notice. Researchers typically contemplate something under 0.8 to be weak.
When all 5 fashions did agree—which occurred on solely 328 out of 1,000 claims—they nearly by no means agreed that one thing was deceptive or largely true. Simply 4 claims acquired a unanimous “deceptive” verdict. Zero acquired unanimous “largely true.”
The researchers supplied instance claims the place the AI fashions confirmed essentially the most divergence, together with “The World Financial institution’s energetic portfolio in Nigeria stands an over $16.4 billion as of 2025.” ChatGPT 5.4 stated it was “largely true” whereas Gemini 3 Professional known as it “false” and its sister mannequin Gemini 3 Professional + Search rated it “deceptive.”
In one other instance, the fashions had been supplied with the declare: “Donald Trump stated that an assault on Iran was postponed on the request of Gulf Allies.” GPT-5.4 stated it was false, Claude Opus 4.7 known as it largely true, Gemini 3 Professional stated false, and Gemini 3 Professional + Search rated it true.
“The panel converges on definitive verdicts; the center of the rubric is the place it fractures,” the researchers discovered. Unanimity solely occurred on the extremes: both the declare was positively true or positively false.
This issues as a result of persons are more and more turning to AI programs for fact-checking. For those who paste a declare from a information article into ChatGPT, Claude, or Gemini, you would possibly get three totally different solutions. Which one do you belief?
AI firms like to let you know their fashions are getting extra correct. They publish benchmark scores displaying regular enchancment. However the Lenz examine examined these fashions on the sort of jagged, ambiguous claims that actual people truly argue about—and located that the fashions argue too.
The paper is cautious to level this out. “A majority of frontier fashions shouldn’t be floor fact. The bulk verdict is usually improper; a person dissenting mannequin is usually proper. We use the bulk as a structural reference level for measuring disagreement, not as a stand-in for correctness.”
There’s a deeper drawback buried within the numbers. When fashions disagree, no less than considered one of them should be improper—the examine calls a mannequin’s verdict “label-inconsistent beneath this 4-bucket rubric.” There’s no tie-breaker mechanism, no appeals court docket. Latest reporting on AI reliability has raised comparable alarms.
On the 328 claims the place all 5 fashions agreed, zero acquired a unanimous “largely true.” The nuance bucket emptied out utterly. If AI fashions can solely discover consensus on the extremes, can they be trusted as truth checkers in any respect?
Each day Debrief Publication
Begin daily with the highest information tales proper now, plus unique options, a podcast, movies and extra.