
In short
- DeepReinforce launched Ornith-1.0 on June 25 underneath MIT license, purpose-built for AI coding brokers working in actual terminal and repository environments.
- The 9B variant scores 69.4 on SWE-bench Verified, outperforming Google’s Gemma 4-31B (52.0).
- Ornith’s personal mannequin card warns the fashions might underperform on non-coding duties—they’re wired for developer pipelines, not general-purpose AI conversations.
DeepReinforce, an AI analysis lab beforehand recognized for CUDA-L1 and the IterX code-agent optimization loop, launched Ornith-1.0 late final week—a household of open-source coding fashions accessible on Hugging Face in 4 sizes primarily based on the variety of parameters: 9 billion, 31 billion, 35 billion combination of consultants, and a 397 billion mixture-of-experts flagship, all underneath MIT license with no regional restrictions.
Parameters are principally the variety of dials and configurations a mannequin can deal with on its coaching. The extra parameters, the extra succesful a mannequin is. A 9-billion-parameter mannequin is taken into account small, adequate to run on smartphone, however not able to doing any heavy reasoning process reliably. A 397 billion mannequin is rather more succesful, however requires some heavy computing, the sort that’s not accessible on client {hardware}.
The lab describes it as “a self-improving household of open-source fashions specifically for agentic coding duties.” That phrase—agentic—is doing a whole lot of work.
Aloha! 🌺 Meet Ornith-1.0, a household of open-source LLMs specialised for agentic coding.
Ornith-1.0 spans the total parameter sizes together with 9B Dense, 31B Dense, 35B MoE, and 397B MoE. It achieves state-of-the-art efficiency amongst open-source fashions of comparable dimension on… pic.twitter.com/7g1rmacLps
— Ornith (@ornith_) June 25, 2026
Most AI that folks work together with is conversational: you sort, it responds, the alternate ends. Agentic AI is completely different—it will get a process and takes actions to finish it with no human guiding every step. In a coding context, meaning an AI that reads information, runs assessments, identifies what failed, fixes the code, and loops once more till it is executed.
So Agentic AI means nobody must be on the keyboard for more often than not. That is the entire level. That is additionally the route the place essentially the most commercially related progress is going on in 2026—the fashions that may run unsupervised by 20-step dev workflows are price greater than those that write a clear perform on request.
Nonetheless, most massive language fashions are nonetheless designed with human suggestions in thoughts.
How Ornith’s mind works
Most AI coding brokers are paired with a human-designed harness—a hard and fast algorithm for a way the agent constructions its work: when to name a instrument, how you can deal with an error, how you can decompose a multi-step downside. Ornith as an alternative “treats the scaffold as a learnable object that co-evolves with the coverage.”
Translation: as an alternative of inheriting another person’s playbook, it develops its personal.
Throughout reinforcement studying, every coaching step occurs in two phases. The mannequin first reads the duty and proposes a refined technique for approaching it. Then it makes use of that technique to generate an answer.
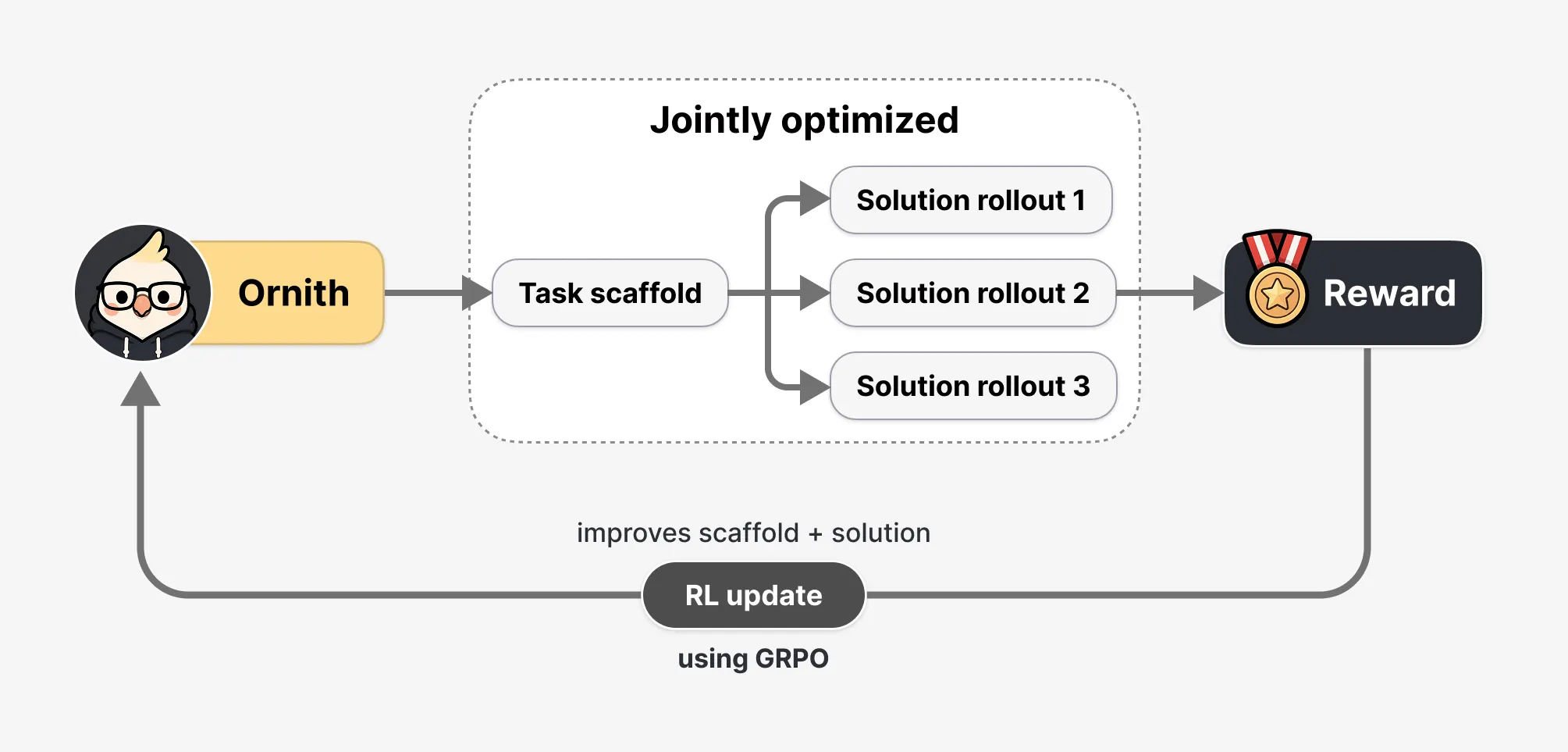
The reward from the result flows again to each phases—so the mannequin is optimized for writing higher methods, not simply higher code. Try this hundreds and thousands and thousands of instances, and task-specific approaches emerge with no human engineering them.
DeepReinforce additionally takes reward hacking severely. If the mannequin can write its personal coaching scaffold, it might theoretically write a scaffold that video games the verifier—touching a file to make it appear to be it accomplished a process with out really doing the work. Three layers of protection block this: the atmosphere and check suite are immutable and outdoors the mannequin’s attain, a deterministic monitor flags any try and entry restricted paths or alter verification scripts, and a frozen choose mannequin sits on high of the automated verifier as a veto.
The numbers
The flagship 397 billion parameter mannequin posts 82.4 on SWE-bench Verified—a check the place an AI is given an actual bug from an open-source GitHub repository and should repair it with out seeing the check suite, scored as the proportion of points it efficiently resolves.
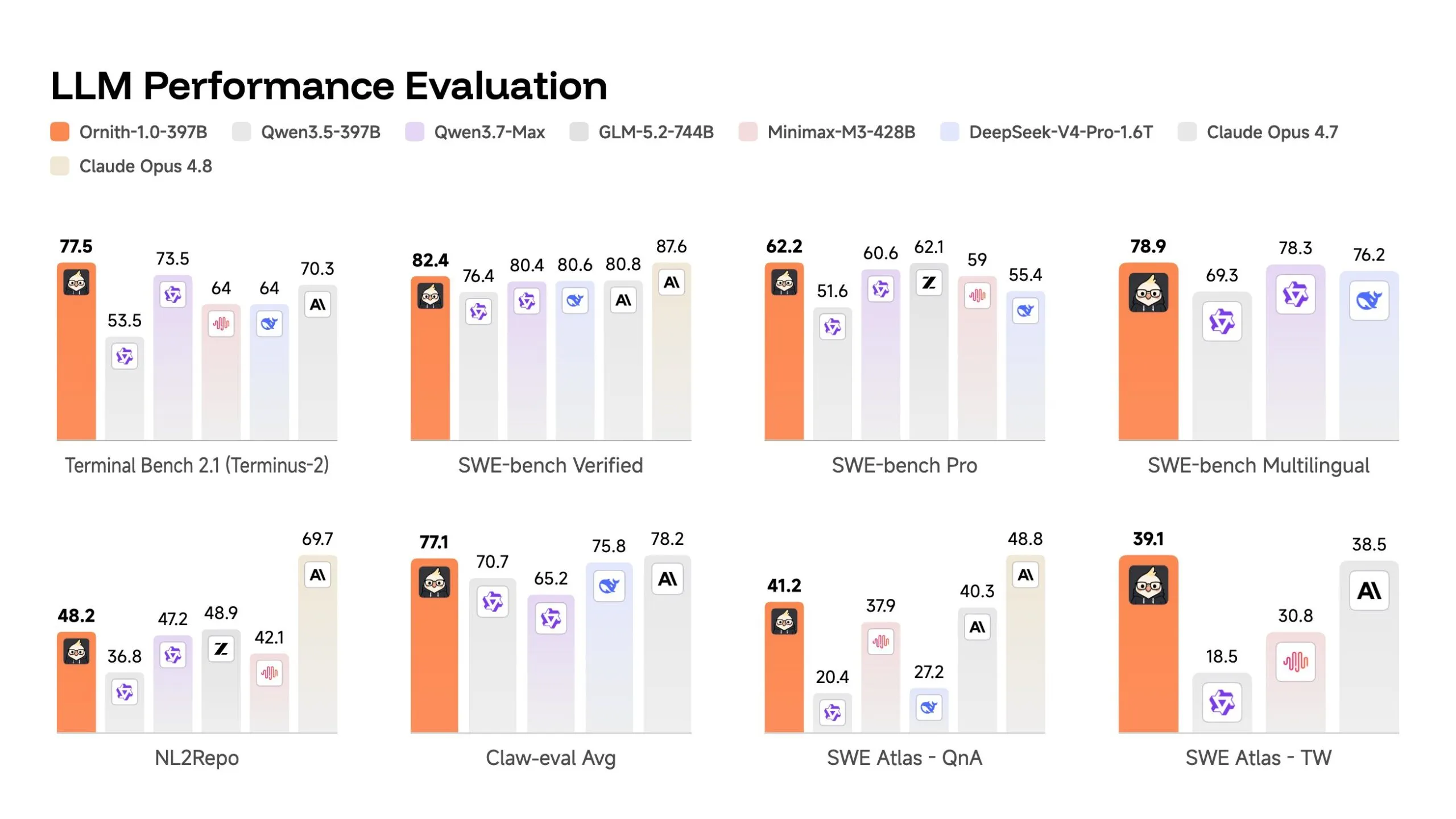
That beats Claude Opus 4.7’s 80.8 and DeepSeek-V4-Professional’s 80.6 on the identical check. On Terminal Bench 2.1—89 duties run inside containerized terminal environments starting from debugging async code to resolving safety vulnerabilities, scored by completion fee—it posts 77.5 in opposition to Claude Opus 4.7’s 70.3.
Provided that SWE-bench contamination issues have been raised publicly—OpenAI argued earlier this yr that fashions had been inflating scores by memorizing benchmark options seen throughout coaching—Ornith additionally experiences numbers on SWE-bench Professional, a more durable model utilizing extra various, less-leaked codebases scored the identical method. The 397 billion mannequin lands at 62.2 there. Meaningfully decrease, however nonetheless aggressive with the sector, and nonetheless higher than Deepseek V4 Professional.
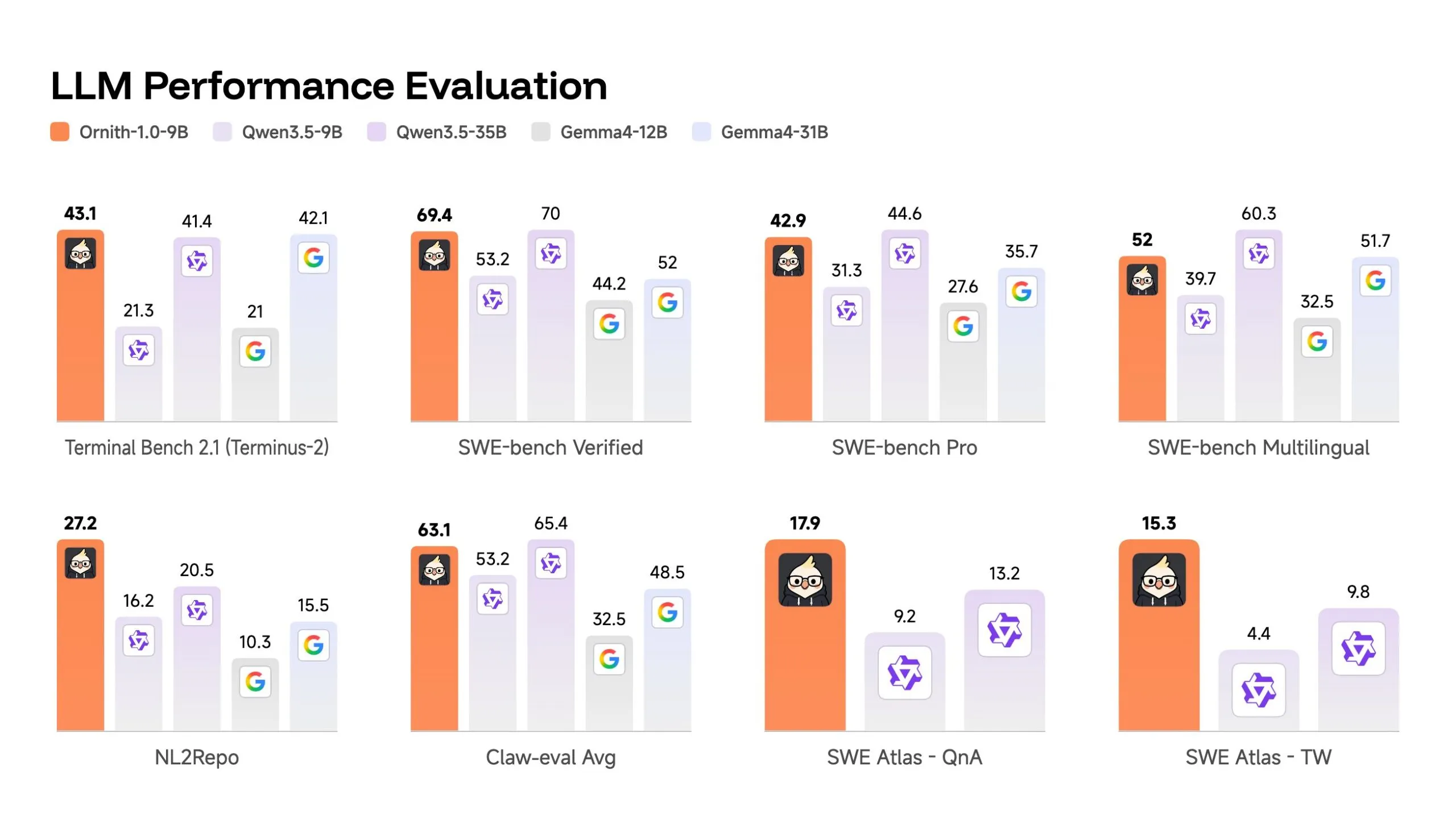
The 9 billion parameter mannequin may be the extra attention-grabbing knowledge level. It posts 69.4 on SWE-bench Verified—larger than Gemma 4-31B’s 52 and aggressive with Qwen 3.5-35B’s 70, regardless of being 3-4 instances smaller.
Who it is for, and who it is not
Ornith-1.0 is explicitly not a general-purpose AI. The mannequin’s personal documentation says it could underperform on duties outdoors agentic coding. If you need AI to summarize a doc, allow you to write your doctoral thesis, or draft an e mail, Ornith-1.0 is the improper decide.
It is optimized for a slim downside set: developer pipelines the place an AI agent takes a process description, operates inside a code repository or terminal session, and completes multi-step work with out intervention. It is a instrument that was constructed for people who find themselves already operating agent infrastructure—not for folks attempting to determine if AI is price utilizing.
The “beats Claude” headline is actual however requires context. As Decrypt reported, each lab is now chasing efficiency on agentic coding evals, as a result of that is the place the helpful efficiency variations stay.
Ornith-1.0-397B does surpass Claude Opus 4.7 on each completely different coding benchmarks, however Anthropic’s present flagship, Claude Opus 4.8, scores larger. The comparability that holds is throughout the open-source class, at comparable parameter counts, on coding-specific agent duties.
For builders constructing self-hosted coding pipelines, agentic infrastructure, or comparable coding-focused work, the small and medium fashions operating on edge {hardware} could also be genuinely helpful, however the common Joe could also be higher wanting someplace else.
Day by day Debrief Publication
Begin each day with the highest information tales proper now, plus authentic options, a podcast, movies and extra.