
In short
- Meituan formally unveiled LongCat-2.0 on June 30, revealing it because the mannequin behind “Owl Alpha.”
- The nameless Mannequin had ranked first on Hermes Agent, second on Claude Code, and third on OpenClaw by name quantity.
- Normal API pricing is $0.75 per million enter tokens and $2.95 per million output tokens—nicely underneath GPT-5.5’s $5/$30 and Claude Sonnet 5’s introductory $2/$10.
Chinese language tech firm Meituan formally unveiled LongCat-2.0 on June 30, confirming the open-license, 1.6-trillion-parameter mixture-of-experts AI mannequin is similar system that spent two months working anonymously on OpenRouter underneath the alias Owl Alpha.
Parameters are the full variety of dials a mannequin can deal with throughout coaching. The mannequin prompts roughly 48 billion of its parameters per token (the smallest unit of information an AI mannequin processes), with that determine swinging between 33 billion and 56 billion relying on how demanding the question is.
The stealth interval paid off. By the point Meituan stepped ahead, the mannequin had already taken first place on the Hermes Agent workspace, second on Claude Code, and third throughout OpenClaw deployments, all ranked by month-to-month name quantity.
That is the primary trillion-parameter mannequin educated and deployed end-to-end on home Chinese language ASICs, not simply served on them after coaching elsewhere. DeepSeek’s V4-Professional, by comparability, used Huawei chips just for inference whereas pretraining ran on Nvidia {hardware}.
Meituan says the pretraining run, spanning greater than 35 trillion tokens throughout a cluster of over 50,000 domestically produced accelerators, completed with “no rollbacks or irrecoverable loss spikes.” That stability declare issues given how typically massive coaching runs on unproven {hardware} stacks fail halfway by means of and the way China appears to be decreasing its dependence on U.S. {hardware} to coach its fashions.
Value is the place LongCat-2.0 makes its actual case. Normal API entry runs $0.75 per million enter tokens and $2.95 per million output, minimize to $0.30/$1.20 throughout the present launch promo, with cached context reads freed from cost. That undercuts GPT-5.5’s $5/$30 per million tokens, Claude Sonnet 5’s introductory $2/$10 charge, and lands near DeepSeek V4-Professional’s everlasting $0.435/$0.87 and Xiaomi’s MiMo-V2.5 Professional, which matched that very same charge after its personal Might worth cuts.
Meituan additionally supplies a token plan, which makes issues even cheaper for coders and heavy customers, providing packs of 1 billion tokens at round $60.
We ran LongCat-2.0 by means of a fast game-building take a look at ourselves. It bought the job achieved, and the output held up fairly nicely after just a few rounds of iteration. The consequence landed visibly behind Claude Fable and Opus 4.8, making it simpler to rank close to Sonnet 4.6, however the quality-per-dollar math is tough to argue with at these costs.
It made the waves of enemies come from completely different angles with the digital camera auto centering on the closest enemy. Nonetheless, the mannequin’s logic didn’t think about what occurs when the variety of enemies will increase with problem. At larger speeds, the target-switching logic grew to become erratic; the main focus would soar to a better enemy in the midst of a typing immediate, making the sport frustratingly unplayable.
That is regular in vibe coding classes, the place fashions don’t foresee many logical penalties of a call, and as an alternative deal with delivering a consequence based mostly on what the person prompts, actually.
That is additionally why an inexpensive mannequin is all the time possibility, as a result of it provides the person extra likelihood to iteratively enhance each consequence till the ultimate product meets expectations.
If something, with out additional interplay, at first look the general high quality lands someplace in between DeepSeel v4 Flash and Deepseek v4 Professional in our fast coding checks.
You’ll be able to try the ends in our itch.io web site
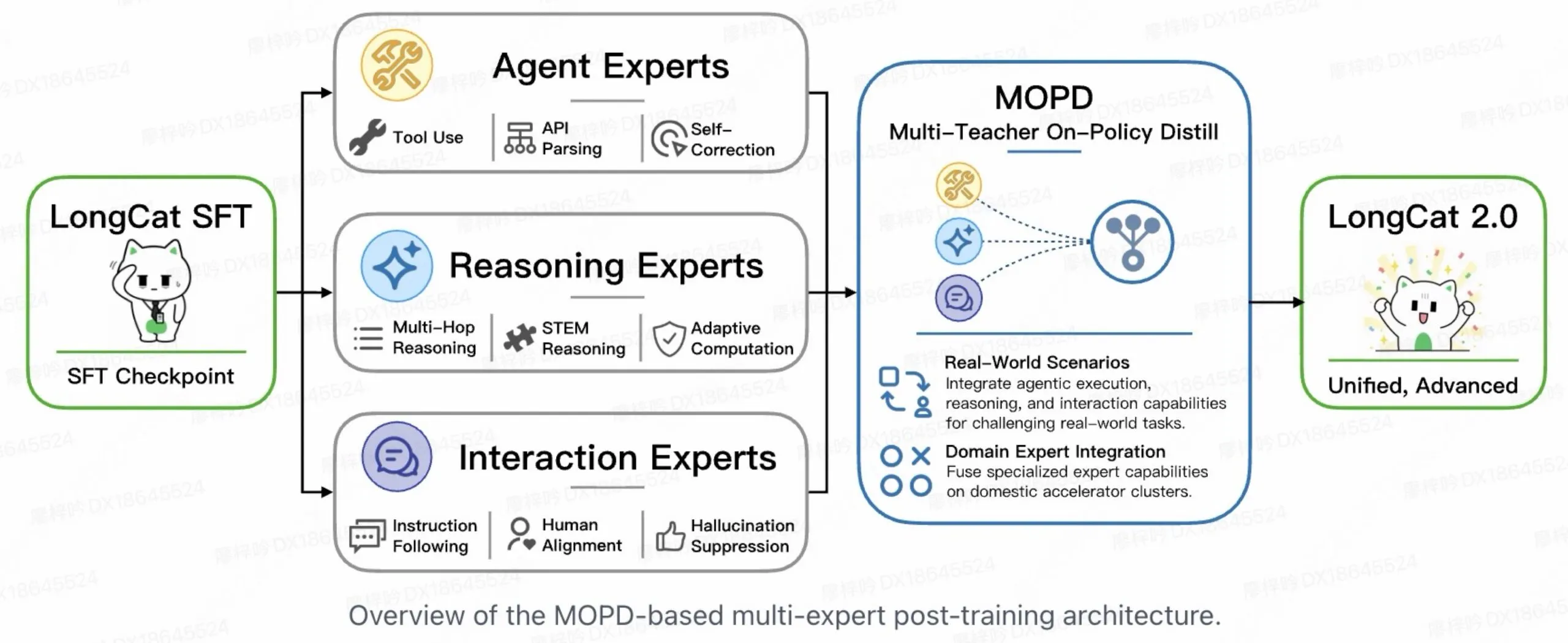
How Meituan constructed it
LongCat-2.0 makes use of a number of methods to make the mannequin quicker and extra succesful with out dramatically growing its measurement.
Its consideration system, based mostly on DeepSeek’s design, focuses solely on essentially the most related elements of very lengthy conversations as an alternative of processing the whole lot equally, serving to it reply extra rapidly.
Additionally, a brand new N-gram embedding system (a method of serving to perceive teams of phrases or subwords collectively) provides the mannequin a a lot richer understanding of phrases and phrases—about 100 occasions extra potential representations—with out including many extra AI elements. It’s principally instructing the AI to acknowledge frequent phrases as an alternative of simply particular person phrases. Fairly than seeing “New,” “York,” and “Metropolis” as three separate items, it may possibly additionally deal with “New York Metropolis” as a single significant idea. This provides the mannequin a a lot richer understanding of language with out making it dramatically bigger.
After coaching, Meituan additionally combines three specialised techniques, one centered on utilizing instruments (Agent), one on fixing issues (Reasoning), and one on conversations (Interplay). A routing mechanism then decides which mixture of these specialists ought to deal with every request, very like assigning the fitting crew to the fitting job.
On SWE-bench Professional, a benchmark that scores how typically a mannequin resolves actual GitHub points pulled from manufacturing codebases, LongCat-2.0 hit 59.5, forward of GPT-5.5’s 58.6 and Gemini 3.1 Professional’s 54.2, although nonetheless behind Claude Opus 4.7 and 4.8. On FORTE, which grades brokers on day-to-day workplace duties throughout 15 professions underneath a 45-minute time restrict, it scored 73.2, tied with Claude Opus 4.6 however trailing GPT-5.5’s 77.8.
Introducing LongCat-2.0 🐱
1.6T parameters · MoE with ~48B energetic · 1M context
The complete mannequin behind Owl Alpha on @OpenRouter — now obtainable.Constructed for agentic coding from the bottom up:
◆ LongCat Sparse Consideration (LSA) — scales effectively for 1M-context tokens
◆… pic.twitter.com/zum2SdZ0Z2— Meituan LongCat (@Meituan_LongCat) June 30, 2026
Groups constructing coding brokers on a finances, or anybody working high-volume repository-scale work the place the free context-cache reads compound, get the clearest win. The mannequin is reachable right now by means of Meituan’s OpenAI- and Anthropic-compatible API endpoints, or by means of agent harnesses like Hermes, Claude Code, and OpenClaw that already combine it.
Anybody who must self-host is out of luck for now. Each the GitHub and Hugging Face repositories nonetheless learn “mannequin weights coming quickly,” however Meituan has not set a date for when the recordsdata will ship.
Every day Debrief E-newsletter
Begin each day with the highest information tales proper now, plus unique options, a podcast, movies and extra.